
介绍
没找到太多miasm文章沉默起到英文翻译作用了。
miasm是一个旨在分析,修改和生成二进制程序的逆向工程框架
功能
- 多格式二进制文件操作
能够打开,拆解,修改并重新生成多种二进制格式,包括PE/ELF,支持32位与64位。LE(小端)和BE(大端) - 多架构汇编与反汇编
支持多种指令集架构,x86(16位,32位,64位),ARM(包括Thumb),MIPS,SH4,MSP430 - 中间表示
miasm将不同架构的语义转化为统一的miasm ir,可以用同一套代码逻辑处理不同架构指令 - 即时编译(JIT)模拟
允许用户对二进制代码进行动态模拟,常用于动态分析代码流,自动化脱壳,模拟特定的库函数调用 - 表达式简化与自动反混淆
miasm拥有一套强大的符号计算引擎,可以化简混淆
关键组件
- 位置数据库(LocationDB)
取代了旧版本的SymbolPool,LocationDB是一个全局的中央仓库,用于管理:
- 所有代码中的标签
- 符号及其对应的地址
- 记录标签与地址的对应关系,充当了代码定位与跳转逻辑的“核心调度器”
- 动态符号执行(DSE,Dynamic Symbolic Execution)
DSE结合了动态运行和符号执行的优势,具有smt求解器,漏洞挖掘:自动检测越界(Out-of-bound),还原算法,约束求解获得序列号 - 数据流分析与依赖图(DepGraph)
通过DepGraph组件提供静态/动态数据追踪能力
- Use-Def链分析:确定寄存器的值在哪定义后后续使用
- 路径敏感分析:区分不同分支对数据状态的影响
- 参数追踪:如在x86分析函数的参数传递过程
- SSA与IR
miasm提升ir,消除冗余寄存器操作
增强可读性,转化伪代码
官方blog推荐文章一
Taming a Wild Nanomite-protected MIPS Binary With Symbolic Execution: No Such Crackme
有部分mips,nanomite,z3内容略过了,只针对miasm部分
miasm符号执行
先看看如何用miasm对单个基本块做符号执行,以子进程主循环的第一个基本块为例
from miasm2.analysis.machine import Machine
from miasm2.analysis import binary
bi = binary.Container("crackmips")
machine = Machine('mips32l')
mn, dis_engine_cls, ira_cls = machine.mn, machine.dis_engine, machine.ira
首先,用通用contaner类打开crackme,它会自动检测可执行格式并用Elfesteem解析,然后用Machine类获取在反汇编和分析时有用的类引用
BB_BEGIN = 0x00402290
BB_END = 0x004022BC
# Disassemble between BB_BEGIN and BB_END
dis_engine = dis_engine_cls(bs=bi.bs)
dis_engine.dont_dis = [BB_END]
bloc = dis_engine.dis_bloc(BB_BEGIN)
print '\n'.join(map(str, bloc.lines))
这里通过告知miasm起始和结束地址来反汇编一个基本块,dis_engine是通过实例化dis_engine_cls得到的,bi.bs是我们操作的二进制流。dont_dis用来告诉Miasm在到达某个地址时停止反汇编,是因为下一条指令是 break,Miasm默认不会把它认为是基本块结束。运行上面代码应得到如下输出:
LW V1, 0x38(FP)
SLL V0, V1, 0x2
ADDIU A0, FP, 0x18
ADDU V0, A0, V0
LW A0, 0x8(V0)
LW V0, 0x38(FP)
SUBU A0, A0, V0
SLL V0, V1, 0x2
ADDIU V1, FP, 0x18
ADDU V0, V1, V0
SW A0, 0x8(V0)
接下来转换为IR
# Transform to IR
ira = ira_cls()
irabloc = ira.add_bloc(bloc)[0]
print '\n'.join(map(lambda b: str(b[0]), irabloc.irs))
我们实例化ira_cls类并调用add_bloc方法。它接收一个基本块并返回一个或多个IR基本块,这里只会得到一个,所以取[0],
V1 = @32[(FP+0x38)]
V0 = (V1 << 0x2)
A0 = (FP+0x18)
V0 = (A0+V0)
A0 = @32[(V0+0x8)]
V0 = @32[(FP+0x38)]
A0 = (A0+(- V0))
V0 = (V1 << 0x2)
V1 = (FP+0x18)
V0 = (V1+V0)
@32[(V0+0x8)] = A0
IRDst = loc_00000000004022BC:0x004022bc
每一行都是miasm的ir指令,每条语句都通过对某些变量产生的的副作用来描述,使用表达式和复制操作。 @32[...]表示32为内存访问,在等号左边表示写入操作,右边表示读取操作。最后一行使用了伪寄存器IRDst(相当于IR的pc-程序计数器)指明下一基本块地址
补:
在机器层,PC保存下一条要执行的指令地址,在Miasm的IR中,用一个伪寄存器IRDst来表示这个基本块执行完后程序要跳到哪里(相当于IR的PC/控制流目标)
from miasm2.expression.expression import *
from miasm2.ir.symbexec import symbexec
from miasm2.expression.simplifications import expr_simp
# Prepare symbolic execution
symbols_init = {}
for i, r in enumerate(mn.regs.all_regs_ids):
symbols_init[r] = mn.regs.all_regs_ids_init[i]
# Perform symbolic exec
sb = symbexec(ira, symbols_init)
sb.emulbloc(irabloc)
mem, exprs = sb.symbols.symbols_mem.items()[0]
print "Memory changed at %s :" % mem
print "\tbefore:", exprs[0]
print "\tafter:", exprs[1]
第一行初始化用于符号执行的符号池,然后用symbexec去创建执行引擎,并提供ir基本块,执行结果可从sb.symbols中读取,这里我们主要关注内存方面影响,所以使用symbols_mem.items()来例举。symbols_mem实际上是一个字典,其键是执行过程中发生变化的内存位置,值是包含该位置原有值和新值的二元值,只有一处变化:
Memory changed at (FP_init+(@32[(FP_init+0x38)] << 0x2)+0x20) :
before: @32[(FP_init+(@32[(FP_init+0x38)] << 0x2)+0x20)]
after: (@32[(FP_init+(@32[(FP_init+0x38)] << 0x2)+0x20)]+(- @32[(FP_init+0x38)]))
表达式变得有点复杂,但仍可读。FP_init表示执行开始时fp的值。我们可以看到某个内存位置被减去了一个值。接着可以用Miasm的简化规则美化输出:
# Simplifications
fp_init = ExprId('FP_init', 32)
zero_init = ExprId('ZERO_init', 32)
e_i_pattern = expr_simp(ExprMem(fp_init + ExprInt32(0x38), 32))
e_i = ExprId('i', 32)
e_pass_i_pattern = expr_simp(ExprMem(fp_init + (e_i << ExprInt32(2)) + ExprInt32(0x20), 32))
e_pass_i = ExprId("pwd[i]", 32)
simplifications = {e_i_pattern : e_i,
e_pass_i_pattern : e_pass_i,
zero_init : ExprInt32(0) }
def my_simplify(expr):
expr2 = expr.replace_expr(simplifications)
return expr2
print "%s = %s" % (my_simplify(exprs[0]) ,my_simplify(exprs[1]))
这里声明了三条替换规则
- 把
@32[(FP_init+0x38)]替换成i - 把
@32[(FP_init+(i << 0x2)+0x20)]替换成pwd[i] - 把
ZERO_init替换成0(此处非必须)
(原文提醒有更通用的模式匹配方式,但这里不需要)
简化后的结果是:
pwd[i] = (pwd[i]+(- i))
也就是这个基本块只是做了一个减法操作。输出其实是有效的Python代码
文章二
Deobfuscation: recovering an OLLVM-protected program
此文示例基于文章写时最新的miasm版本(指定了commit id)
想要去混淆,一种做法时把基本块内容变成llvm ir,以便重新编译并对其应用优化pass来清理无用代码,从而得到新的二进制但这比较耗时。相反,选择在ida中构建去混淆输出图,使用idapython的graphviewer类,这样就可以更容易的构建节点和变,并用miasm中间表示来填充基本块内容
ollvm由三种不同保护机制组成:控制流平坦化,虚假控制流和指令替换
控制流平坦化
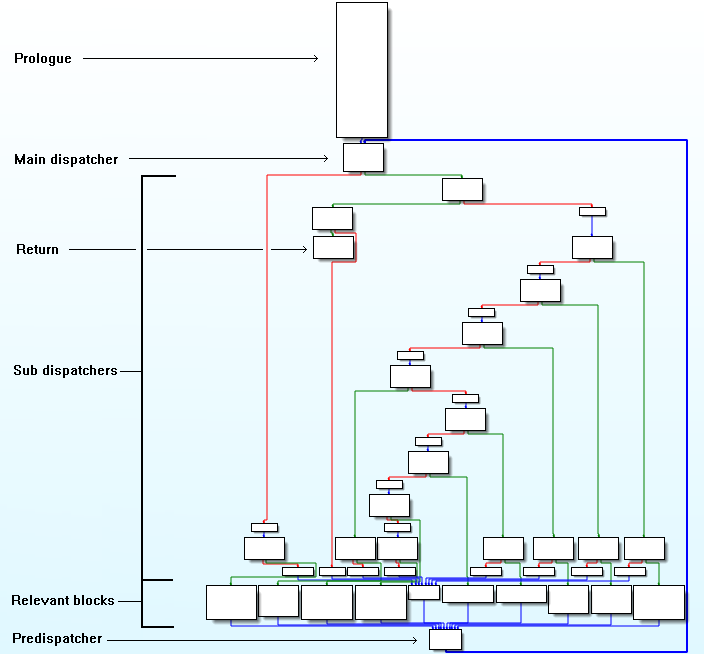
Miasm框架有一个符号执行引擎(支持x86 32位架构和其他一些架构),它基于自己的IR以及将二进制代码转换为IR的反汇编器
下面是Miasm Python代码,能够对一个基本块进行符号执行,以计算其目标地址
# 从 Miasm 框架导入
from miasm2.core.bin_stream import bin_stream_str
from miasm2.arch.x86.disasm import dis_x86_32
from miasm2.arch.x86.ira import ir_a_x86_32
from miasm2.arch.x86.regs import all_regs_ids, all_regs_ids_init
from miasm2.ir.symbexec import symbexec
from miasm2.expression.simplifications import expr_simp
# 二进制路径和目标函数的偏移
offset = 0x3e0
fname = "../src/target"
# 获取 Miasm 的二进制流
bin_file = open(fname).read()
bin_stream = bin_stream_str(bin_file)
# 在 'offset' 处对函数的基本块进行反汇编
mdis = dis_x86_32(bin_stream)
disasm = mdis.dis_multibloc(offset)
# 创建目标 IR 对象并将所有基本块添加到其中
ir = ir_a_x86_32(mdis.symbol_pool)
for bbl in disasm: ir.add_bloc(bbl)
# 用所有已知寄存器初始化我们的符号
symbols_init = {}
for i, r in enumerate(all_regs_ids):
symbols_init[r] = all_regs_ids_init[i]
# 创建符号执行引擎
symb = symbexec(ir, symbols_init)
# 获取我们想要的基本块并模拟它
# 我们获取到下一个要执行的基本块的地址
block = ir.get_bloc(offset)
nxt_addr = symb.emulbloc(block)
# 运行 Miasm 的简化引擎,以确保拥有最简单的表达式
simp_addr = expr_simp(nxt_addr)
# simp_addr 变量是一个整数表达式(下一个基本块的偏移)
if isinstance(simp_addr, ExprInt):
print("跳转到下一个基本块: %s" % simp_addr)
# simp_addr 变量是一个条件表达式
elif isinstance(simp_addr, ExprCond):
branch1 = simp_addr.src1
branch2 = simp_addr.src2
print("条件: %s 或 %s" % (branch1, branch2))
上面是示例,为覆盖所有基本块,可以从目标函数的开始跟随执行流,逐一探索分支,复原功能。因此,我们必须有一个分支栈,以在到达函数返回时处理可用的下一个分支。对于每个分支,我们都需要保存状态,以便在处理它时恢复所有符号执行上下文(例如寄存器)
中间函数
应用之前解释的方法后,我们能够重建一个中间控制流图(CFG)。让我们用我们的图形表示脚本将其展示出来
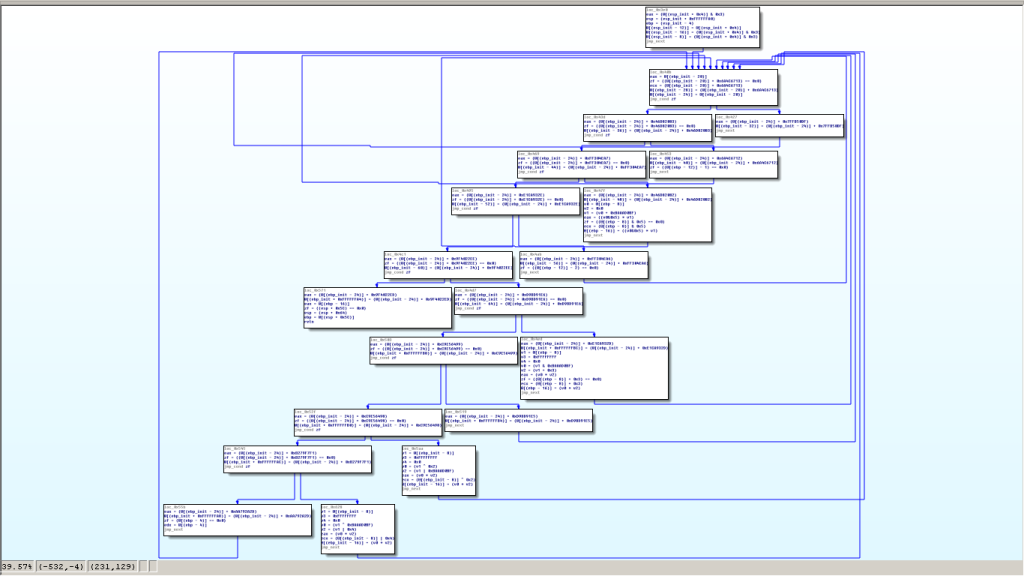
在这个中间函数中,所有有用基本块和条件都可以见,尽管主调度器及子调度器有利于执行代码,但现在只需恢复原始的控制流图,所以只保留相关基本块
在ollvm中,大部分相关块(除了前言和返回基本块)都位于可检测位置,我们必须从原始被保护函数开始,编写一些代码来构建一个通用算法,找到相关块
- 从函数前言开始
- 主调度器上,获取父节点,与前言不同,它是前调度器(?)
- 将所有前调度器的父节点标记为相关
- 将唯一没有子节点的块标记为相关:返回块
这个算法可以通过使用Miasm反汇编器静态实现,该反汇编器为我们提供目标函数的所有反汇编基本块列表。一旦我们获得了相关块的列表,就能够在符号执行期间遵循上述算法的规则重建原始控制流
- 定义一个变量以包含父块(初始时为前言)(仅相关块可以赋值给此变量)。
- 在每个遇到的新块中,如果它在相关列表中,我们可以在其与父块之间建立链接。将这个新块设置为父块。
- 在每个条件分支中,每条路径将拥有自己的相关父块变量。
- 以此类推。
# 在这里我们反汇编目标函数并收集相关块
# 为了清晰起见而进行了简化,但这里没有复杂的,算法在上面给出
relevants = get_relevants_blocks()
# 控制流字典 {parent: set(childs)}
flow = {}
# 初始化控制流字典,设置子节点为空集
for r in relevants: flow[r] = set()
# 开始符号执行循环
while True:
block_state = # 获取下一个块的状态进行模拟
# 获取当前分支参数
# "parent_addr" 是之前看到的父块变量
# "symb" 是当前分支的上下文(符号)
parent_addr, block_addr, symb = block_state
# 如果它是一个相关块
if block_addr in flow:
# 我们避免访问前言的父块,因为它不存在
if parent_addr != ExprInt32(prologue_parent):
# 建立块与其相关父块之间的链接
flow[parent_addr].add(block_addr)
# 然后将该块设置为新的相关父块
parent_addr = block_addr
# 最后,我们可以模拟下一个块,依此类推。
然后可以获得控制流图
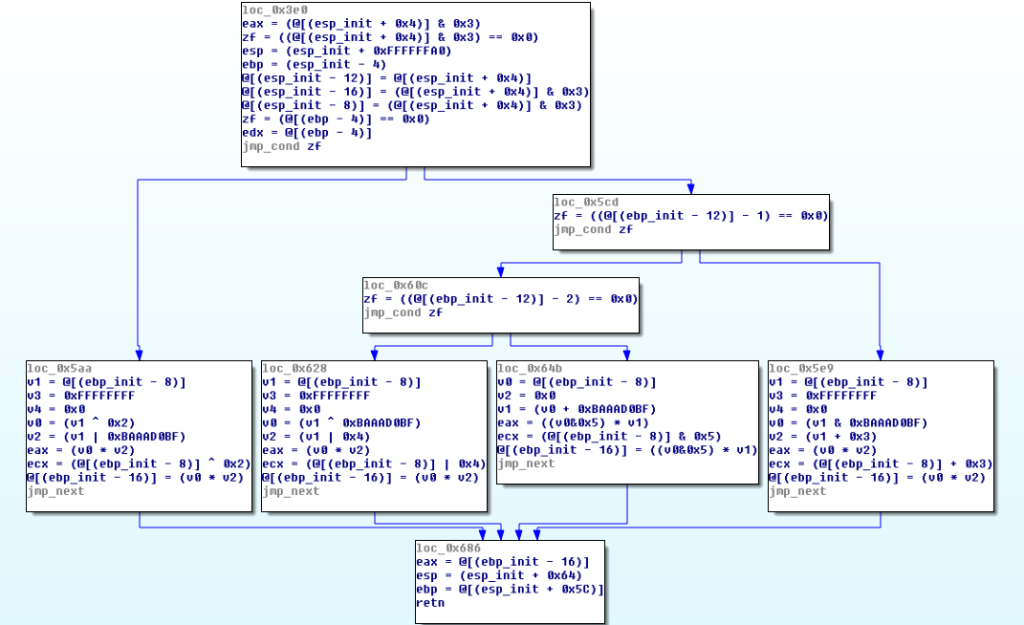
虚假控制流
这个pass对于每个需要混淆的基本块,创建一个包含不透明谓词的新块,该谓词会导致一个条件跳转,引导到真实块或者另一个包含无用代码的块。包含无用代码的基本块可能返回到它的父块,如果在符号执行中遵循这个路径,会陷入无限循环,所以需要解决掉不透明谓词以找到正确路径
// 之前:
// entry
// |
// ______v______
// | 原始 |
// |_____________|
// |
// v
// return
//
// 之后:
// entry
// |
// ____v_____
// |condition*| (false)
// |__________|----+
// (true)| |
// | |
// ______v______ |
// +-->| 原始* | |
// | |_____________| (true)
// | (false)| !-----------> return
// | ______v______ |
// | | 改变的 |<--!
// | |_____________|
// |__________|
//
// * 这些终止分支条件的结果总是为真,但这些谓词是不透明的。为此,我们声明两个全局值:x 和 y,并将 FCMP_TRUE 谓词替换为 (y < 10 || x * (x + 1) % 2 == 0) (这可以改进,因为全局值给出了不透明谓词位置的线索)。
在我们的符号执行期间,我们需要简化以下不透明谓词:(y < 10 || x * (x + 1) % 2 == 0)。Miasm仍然可以帮助我们做到这一点,因为它包含一个在其自身的IR上运作的表达式简化引擎。我们需要添加对不透明谓词的知识。由于我们有一个“或”(||)在两个方程之间,并且结果必须为True,只要简化其中一个就足够了
这里的目标是使用Miasm进行模式匹配,替换表达式 x * (x + 1) % 2 为零。因此,不透明谓词的右侧为True,可以解决
可以查看ollvm源码来验证
BogusControlFlow.cpp:620
// 如果 y < 10 或者 x*(x+1) % 2 == 0
opX = new LoadInst ((Value *)x, "", (*i));
opY = new LoadInst ((Value *)y, "", (*i));
op = BinaryOperator::Create(Instruction::Sub, (Value *)opX,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 1,
false), "", (*i));
# 从 Miasm 框架导入
from miasm2.expression.expression import *
from miasm2.expression.simplifications import expr_simp
# 定义我们的匹配变量
jok1 = ExprId("jok1")
jok2 = ExprId("jok2")
# 自定义表达式简化回调
# 我们在搜索: (x * (x - 1) % 2)
def simp_opaque_bcf(e_s, e):
# 尝试匹配 (a * b) % 2
to_match = ((jok1 * jok2)[0:32] & ExprInt32(1))
result = MatchExpr(e, to_match, [jok1, jok2])
if (result is False) or (result == {}):
return e # 不匹配。返回未修改的表达式
# 有趣的候选项,尝试更精确
# 验证 b == (a - 1)
mult_term1 = expr_simp(result[jok1][0:32])
mult_term2 = expr_simp(result[jok2][0:32])
if mult_term2 != (mult_term1 + ExprInt(uint32(-1))):
return e # 不匹配。返回未修改的表达式
# 匹配到不透明谓词,返回 0
return ExprInt32(0)
# 将我们的自定义回调添加到 Miasm 默认简化引擎
# expr_simp 对象是 ExpressionSimplifier 类的一个实例
simplifications = {ExprOp: [simp_opaque_bcf]}
expr_simp.enable_passes(simplifications)
DSE
动态符号执行是指同时运行符号执行和具体执行,通过这种方式,符号执行可以借助具体路径来避免可能路径(在循环中)的数量爆炸,在方程变得过于复杂时使用具体值或系统调用的值
在给定时间只有一条路径被考虑,但是沿着路径的输入约束可以累计并反转,从而生成新输入以达到新代码
考虑以下代码:
int func(int arg) {
arg += 1;
if (arg & 0xFF == 0x12) {
arg += 13;
}
return arg;
}
让我们考虑第一次执行使用的任意具体值 arg = 0
| 行号 | 伪 IR | 具体状态 |
|---|---|---|
| 0 | ARG = ARG + 1 | ARG = 1 |
| 1 | (ARG & 0xFF == 0x12) ? 2 : 4 | 转到 4 |
| 4 | RETURN ARG | 返回 1 |
如果考虑完全符号执行,会得到
0: ARG = ARG + 1
1: (ARG & 0xFF == 0x12) ? 2 : 4 -> 无法解决的条件!
符号执行无法运行到函数的结束。实际上,可以考虑其他技术,例如多路径符号执行,但这不是这个示例的重点。
这里使用具体的符号执行,有一个可能条件输出的例子而不考虑条件
将此信息集成到符号执行状态中,我们选择不满足条件路径,即假设(ARG & 0xFF == 0x12)为假,或者(ARG & 0xFF != 0x12)。我们将其称为约束。
执行最终结束,返回ARG + 1。现在,我们可以说,当(ARG & 0xFF != 0x12)时,此代码片段返回ARG + 1。它可能已经被混淆。
我们还可以反转路径上的约束,例如使用SMT求解器。设想求解器给出的ARG = 0x123412,这将满足(ARG & 0xFF == 0x12)。
通过尝试这个输入,我们现在得到新路径和新结果:如果(ARG & 0xFF == 0x12),该代码片段返回ARG + 14。这就是生成新输入以达到程序新代码区域的方法。这个方法以通过制作新的输入来增强模糊测试,从而达到尚未测试的代码区域。模糊测试在测试输入时非常快速,但它们在“复杂条件”上会被卡住,例如与多字节魔法值(a multi-byte magic value)的比较。而这正是DSE强项
TigressVM
我们应用此技术来恢复已混淆的算法
以命令行参数作为输入,并根据输入和未知算法输出一个值
运行程序
让我们编写一个脚本来运行程序并使用miasm,得益于PR #515,现在可以为linux二进制文件模拟一个环境
from miasm2.analysis.sandbox import Sandbox_Linux_x86_64
# 创建沙盒
parser = Sandbox_Linux_x86_64.parser(description="ELF 沙盒")
parser.add_argument("filename", help="ELF 文件名")
options = parser.parse_args()
# 强制环境模拟
options.mimic_env = True
# 虚拟参数:123456789
options.command_line = ["".join(chr(0x30 + i) for i in range(1, 10))]
# 实例化并运行
sb = Sandbox_Linux_x86_64(options.filename, options, globals())
sb.run()
启动后,我们会遇到一个错误,因为strtoul存根尚未实现
$ python tigress.py tigress-0-challenge-0
[INFO]: xxx___libc_start_main(main=0x4005f4, argc=0x2, ubp_av=0x13ffc4, init=0x400ca0, fini=0x400d30, rtld_fini=0x0, stack_end=0x13ffb8) ret addr: 0x400539
ValueError: ('未知 API', '0x71111012L', "'xxx_strtoul'")
因此,让我们实现一个简单版本的strtoul
def xxx_strtoul(jitter):
ret_ad, args = jitter.func_args_systemv(["nptr", "endptr", "base"])
assert args.endptr == 0
content = jitter.get_str_ansi(args.nptr)
value = int(content, args.base)
print("%r -> %d" % (content, value))
jitter.func_ret_systemv(ret_ad, value)
现在,strtoul可以正常运行,但我们遭遇了内存错误。事实上,该函数使用了栈保护,因此我们需要模拟它(分段 + 内存页/segmentation + memory page)
from miasm2.jitter.csts import PAGE_READ
...
# 初始化栈保护
sb.jitter.ir_arch.do_all_segm = True
FS_0_ADDR = 0x7ff70000
sb.jitter.cpu.FS = 0x4
sb.jitter.cpu.set_segm_base(sb.jitter.cpu.FS, FS_0_ADDR)
sb.jitter.vm.add_memory_page(
FS_0_ADDR + 0x28, PAGE_READ, "\x42\x42\x42\x42\x42\x42\x42\x42", "Stack canary FS[0x28]"
)
我们还需要支持128位操作,因此我们将使用llvm jit(python版本的速度较慢)
options.jitter = "llvm"
模拟从头到尾工作,一切正常
$ python tigress.py tigress-0-challenge-0
[INFO]: xxx___libc_start_main(main=0x4005f4, argc=0x2, ubp_av=0x13ffc4, init=0x400ca0, fini=0x400d30, rtld_fini=0x0, stack_end=0x13ffb8) ret addr: 0x400539
[INFO]: xxx_strtoul(nptr=0x13ffec, endptr=0x0, base=0xa) ret addr: 0x400660
'123456789' -> 123456789
[INFO]: xxx_printf(fmt=0x400dbd) ret addr: 0x4006b4
8131652486802131118
$ ./tigress-0-challenge-0 123456789
8131652486802131118
添加DSE
现在,我们想要获得基于输入的输出方程
或者说,我们会符号化由strtoul返回的值,提取printf的第二个参数的方程
为此,我们将在strtoul结束后将DSE引擎附加到jitter,一旦附加,miasm将自动将具体状态通知符号引擎,累计约束,检查符号执行与这一具体状态的一致性,等等
首先,我们实例化一个DSEEngine对象,并要求它stub外部API(与沙盒相同方式)
from miasm2.analysis.dse import DSEEngine
dse = DSEEngine(sb.machine)
dse.add_lib_handler(sb.libs, globals())
现在,我们将在strtoul结束后将DSE对象附加到jitter,设置所有寄存器值为具体值(我们不想跟踪它们),并将返回值设置为符号
from miasm2.expression.expression import ExprId
VALUE = ExprId("VALUE", 64)
def xxx_strtoul(jitter):
global dse
...
jitter.func_ret_systemv(ret_ad, value)
dse.attach(jitter)
dse.update_state_from_concrete()
dse.update_state({
dse.ir_arch.arch.regs.RAX: VALUE,
})
现在,我们注意到脚本的执行时间变长。它以错误结束,寻找xxx_printf_symb,即printf的符号stub。
检查它的第二个参数
def xxx_printf_symb(dse):
result = dse.eval_expr(dse.ir_arch.arch.regs.RSI)
print(result)
raise RuntimeError("Exit")
获得方程:
({(VALUE+(VALUE|(VALUE+0x34D870D1)|0xFFFFFFFFD9FCA98B)+0x34D870D1) 0 64, ((VALUE+(VALUE|(VALUE+0x34D870D1)|0xFFFFFFFFD9FCA98B)+0x34D870D1)[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128}*{({((((((VALUE|0x46BC480) << ({(((VALUE+0x34D870D1)&0x7)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F))&0x3F) << 0x4)|((VALUE+0x1DD9C3C5) << ({((- ((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1))+0x40)[0:8] 0 8, 0x0 8 64}&0x3F))|((VALUE+0x1DD9C3C5) >> ({((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F)))*0x2C7C60B7) 0 64, (((((((VALUE|0x46BC480) << ({(((VALUE+0x34D870D1)&0x7)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F))&0x3F) << 0x4)|((VALUE+0x1DD9C3C5) << ({((- ((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1))+0x40)[0:8] 0 8, 0x0 8 64}&0x3F))|((VALUE+0x1DD9C3C5) >> ({((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F)))*0x2C7C60B7)[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128}*{(VALUE|0x46BC480) 0 64, ((VALUE|0x46BC480)[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128})[0:64] 0 64, (({((((((VALUE|0x46BC480) << ({(((VALUE+0x34D870D1)&0x7)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F))&0x3F) << 0x4)|((VALUE+0x1DD9C3C5) << ({((- ((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1))+0x40)[0:8] 0 8, 0x0 8 64}&0x3F))|((VALUE+0x1DD9C3C5) >> ({((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F)))*0x2C7C60B7) 0 64, (((((((VALUE|0x46BC480) << ({(((VALUE+0x34D870D1)&0x7)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F))&0x3F) << 0x4)|((VALUE+0x1DD9C3C5) << ({((- ((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1))+0x40)[0:8] 0 8, 0x0 8 64}&0x3F))|((VALUE+0x1DD9C3C5) >> ({((((VALUE+0x34D870D1)*0x38BCA01F)&0xF)|0x1)[0:8] 0 8, 0x0 8 64}&0x3F)))*0x2C7C60B7)[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128}*{(VALUE|0x46BC480) 0 64, ((VALUE|0x46BC480)[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128})[63:64]?(0xFFFFFFFFFFFFFFFF,0x0)) 64 128})[0:64]
我们可以使用VALUE = 123456789来评估它,并验证它是否与具体结果相同
from miasm2.expression.expression import ExprId, ExprInt
...
def xxx_printf_symb(dse):
result = dse.eval_expr(dse.ir_arch.arch.regs.RSI)
print(result)
obtained = dse.symb.expr_simp(result.replace_expr({VALUE: ExprInt(123456789, 64)}))
print(obtained)
assert int(obtained) == sb.jitter.cpu.RSI
raise RuntimeError("Exit")
得到了相同的结果,方程输入有效
DepGraph
Use-Def
Use-Def算法会返回对于变量x的某一次使用,所有那些能够在中间没有其他重新定义的情况下到达该使用点的X的定义
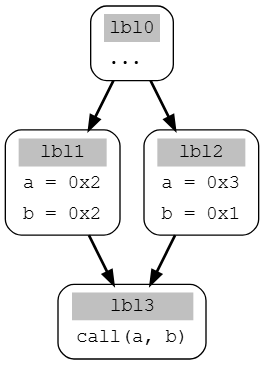
路径敏感(Path-sensitive)
为了获取具体的值,可以使用路径敏感算法,这种算法会生成到达a的所有可能路径,但是在存在多个分支和循环的情况下会路径爆炸
其他
还存在污点分析Tainting,切片Slicing等其他算法,但是他们要么过于受限,在简单的if/then/else情况下无法区分不同的解,要么过于详尽,在嵌套循环中会发生爆炸
DepGraph
依赖图,即Depgraph,是一种介于路径敏感和不敏感之间的算法,目标是可能的情况下提供可区分的值,并在相关情况下返回包含循环的不同路径
其主要是在每一个路径中回溯值,但仅当该路径能产生新的变量依赖关系时才继续
在第一个例子中,该算法仅返回一个解:
a_lbl2 <- b_lbl1
b_lbl1 <- c_lbl0
c_lbl0 <- 0x0
在 if/then/else例子中,算法会独立考虑两条分支。由于每个分支生成了不同的变量依赖集,因此会返回两个解:
第一个解:
a_lbl3 <- b_lbl1, c_lbl0
b_lbl1 <- 0x2
c_lbl0 <- 0x1
第二个解:
a_lbl3 <- b_lbl2, c_lbl0
b_lbl1 <- 0x3
c_lbl0 <- 0x1
这些解不包含循环,所以我们可以在每种情况下计算出a的值
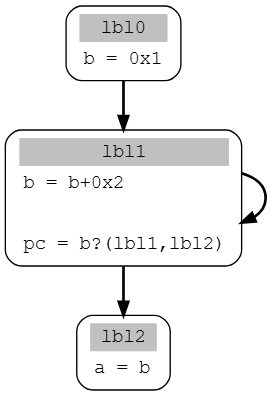
在循环实例中,情况变得有所区别,现在运行该算法,在lbl2块中追踪a,它依赖于b。然后紧接着追踪b。lbl2只有一个父节点lbl1。所以我们现在在lbl1中追踪b。在lbl1中b被修改了(记作b_lbl1),由于等式时b=b+1,我们仍需在lbl1的父节点中追踪b,在这种情况下,lbl1有两个父节点:lbl0和lbl1,因此将此处拆分讨论
首先考虑lbl0,b被写入了一个常量,因此不再追踪更多变量,我们得到了第一个解(不涉及循环)
第一个解
a_lbl2 <- b_lbl1
b_lbl1 <- b_lbl0, 0x2
b_lbl0 <- 0x1
第二个解将lbl1视为父节点,此时b_lbl1依赖于它自身,而我们仍在追踪b,由于我们创建了一个新的依赖关系(b_lbl1依赖于b_lbl1)且lbl1有两个父节点,我们将再次拆分分析,我们回到了与之前相同的点,但状态不同
接下来,我们将lbl0作为父节点,b被写入了一个常量,不再追踪更多变量,我们得到了包含循环的解
第二个解:
a_lbl2 <- b_lbl1
b_lbl1 <- b_lbl1, 0x2
b_lbl1 <- b_lbl0, 0x2
b_lbl0 <- 0x1
剩余的分析需要在lbl1块中再次循环,变量b依赖于b_lbl1,而我们已经到达了lbl1块的顶部,准备向每个父节点传播分析。
但是这个状态之前已经到达过,并且在分析中没有增加任何新的变量依赖关系,该状态已经处理过了,可以丢弃,由于没有更多排队的分析任务,算法结束
最终我们得到了两个解,一个不包含任何循环(lbl1恰好执行一次),这种情况下可以计算出a的值(为3);另一个解,可能执行lbl1块两次或者更多次,无法给出所有可能的解
再看一个例子
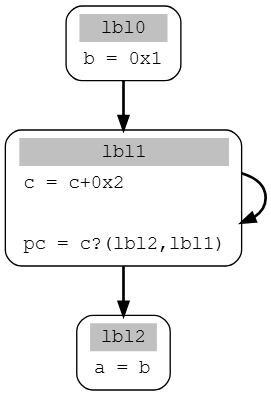
该算法仅返回一个解
a_lbl2 <- b_lbl0
b_lbl0 <- 0x1
当我们回溯lbl1块父节点中的b时,如果分析再lbl1父节点中回溯。由于该块与直接从lbl0块中回溯的方案相比并没有增加任何新的变量依赖关系,因此该分支的分析会被丢弃。
(这里不予讨论终止性分析,不存在通用算法能解决所有停机问题,上面直接默认程序已经成功跑到lbl2,不考虑循环是否能跑完,miasm基于程序能正常运行假设)
最后一点是,你可以在同一次分析中(从同一个起点开始)追踪多个变量:算法将通过计算这些变量组成的变量组的可能值来进行处理(它不会为每个变量分别返回独立的解)示例如下
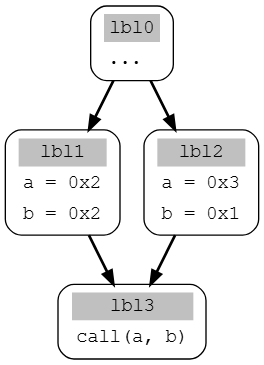
如果你想获取有关调用参数的信息,你会从lbl3处对变量组(a,b)运行该算法,算法将返回两个解
第一个解:
a_lbl3 <- a_lbl1
a_lbl1 <- 0x2
b_lbl3 <- b_lbl1
b_lbl1 <- 0x2
第二个解:
a_lbl3 <- a_lbl2
a_lbl2 <- 0x3
b_lbl3 <- b_lbl2
b_lbl2 <- 0x1
这些解中没有循环,因此它们的值是可以计算的,在这种情况下为:(2,2)和(3,1)。这比分别在a上运行算法(得到解2和3),和在b上运行算法(得到解2和1)要精确的多。如果将它们简单的合并来获取(a,b)对的解,会得到这两个解集的笛卡尔积,这会产生一些不可达的(虚假)解
不过该算法也有一些局限性,如果追踪的是涉及内存值的变量,可能会遇到别名问题,就是,如果你追踪@32[ESP],算法会仅从语法层面追踪@32[ESP]。例如:
@32[ESP] = 0x1
ESP = ESP + 0x4
a = @32[ESP]
在这个例子中,如果回溯a,算法只会简单的返回一个解:0x1(这可能是错误的)
最后一个例子:这里的x的可能值是多少?

解一:x=0x2
解二:x=0x1
展示1:追踪x86_64寄存器参数
在Windows调用约定中,前四个参数通过寄存器RCX,RDX,R8,R9从调用方传递给被调用方。以“Equation Group”这一组程序的二进制文件为例:ntevtx64.sys。该程序所操作的字符串已被加密处理,当程序使用其中的一个字符串时,它首先会调用一个接收三个参数的函数
- RCX:一个用于存储解密后字符串的指针
- RDX:指向加密字符串的指针
- R8:字符串的长度
这是一个普通的调用示例:
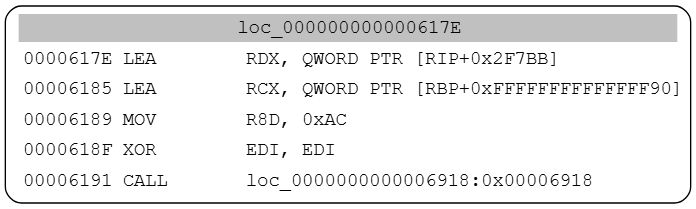
地址0x6918处的函数负责解密字符串,这个例子中,恢复所有参数非常简单,例如,对应的中间表示ir如下
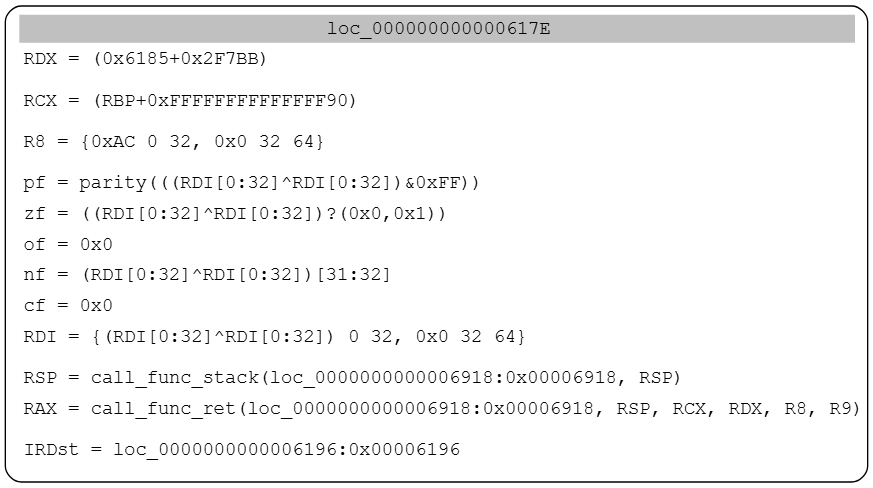
在这种情况下
- RCX:栈中指针
- RDX:0x6185+0x2F7BB
- R8:0xAC
我们之后可能会使用这些参数来模拟该函数,以便为该引用处解密字符串。这个例子可以手工完成,但是该解密函数有82处引用
这里有一个例子
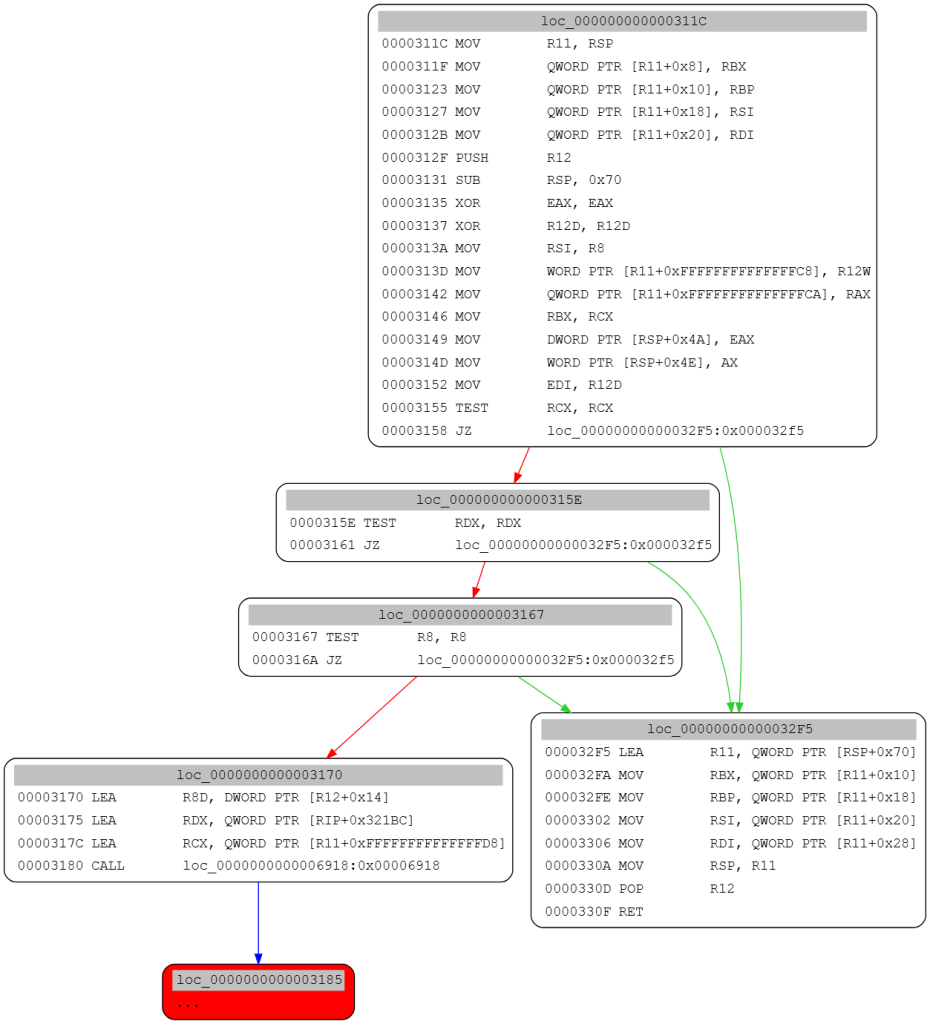
你能从CALL处回溯追踪R8和RDX吗?在这个例子中,关键在于R8依赖于R12,但其值始终被设置为0(在0x3137处设置)
使用DepGraph为每个引用自动化参数分析,R8和RDX都在同一次分析中被追踪,以避免为每个变量产生相互独立的解。如果它们的生成过程中涉及一些嵌套循环。我们可以转而进行手动分析
你可以使用miasm/example/symbol_exec/depgraph.py来测试它
$ python2 depgraph.py -h
usage: Dependency grapher [-h] [-m ARCHITECTURE] [-i] [--unfollow-mem]
[--unfollow-call] [--do-not-simplify]
[--rename-args] [--json]
filename func_addr target_addr element [element ...]
位置参数:
filename 要分析的二进制文件
func_addr 函数地址
target_addr 开始分析的目标地址
element 要追踪的元素
...
在之前的函数上运行这个示例:
$ python2 miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x311C 0x3180 R8 RDX
Solution 0: R8=0x14, RDX=0x35338 -> sol_0.dot
(这个示例也以ida插件形式提供,位于_miasm/example/ida/depgraph.py_
为了自动化分析二进制文件中对字符串解密例程的每一次调用,我们可以使用ida脚本提取对其(地址为0x6918)的所有引用:
addr_dec_str = 0x16918
for ref in idautils.XrefsTo(addr_dec_str):
ref_addr = ref.frm
func = idaapi.get_func(ref_addr)
print hex(func.startEA), hex(ref_addr)
# Python 输出结果示例:
# 0x1311cL 0x13180L
# 0x13b48L 0x13c2eL
# 0x13b48L 0x13cd3L
# ...
我们目前处理的二进制文件基地址(Image Base)为0。但IDA默认会将二进制文件重定位到0x10000.这就解释了为什么ida地址与miasm处理的地址(保持默认基地址0)之间有0x10000的偏差
现在,我们可以使用这些值在命令行中运行之前的工具:
python2 ~/projet/miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x311c 0x3180 R8 RDX
Solution 0: R8=0x14, RDX=0x35338 -> sol_0.dot
python2 ~/projet/miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x3b48 0x3c2e R8 RDX
Solution 0: R8=0x11, RDX=0x355D8 -> sol_0.dot
...
For the moment we cannot run most Miasm scripts directly in IDA because IDA uses a bundled 32 bit python, and the host now uses python 64bit in most cases (except for pure python Miasm script, which depgraph belongs to)
Anyway, my preferred way to use Miasm in IDA is to run a [rypc](https://rpyc.readthedocs.io/) server in IDA, and to use it in an external Python. Server code (to run in IDA):
原文这里用的是老版本ida,有32位64位不兼容的情况,但是仍可以使用RPyc服务端来防止一些问题,如环境依赖和旧工具链的python脚本(原文用的python2)
服务端代码
import rpyc
from rpyc.utils.server import OneShotServer
from rpyc.core import SlaveService
import threading
def serve_threaded():
print 'Running server'
def run_thread():
t = OneShotServer(SlaveService, hostname="localhost",
port=4455, reuse_addr=True, ipv6=False,
authenticator=None,
auto_register=False)
t.logger.quiet = False
t.start()
run_thread()
try:
serve_threaded()
except Exception as e:
print "ERROR", e
你可以通过将Rpyc的文件复制到ida/python/rpyc来安装它,这是可行的,因为rpyc是纯python编写的
现在你就可以在宿主机的脚本(例如depgraph_find_args.py)中使用ida了,流程如下:
- 检索解密函数的引用
- 检索其父函数
- 反汇编并获取该函数的ir(并将其缓存)
- 找到与调用引用相对应的ir块
- 运行depgraph
首先在ida中运行rpyc服务端,然后在宿主机运行此脚本,结果如下
Solution for '0x13180L': 0x35338 0x14
Solution for '0x13c2eL': 0x355D8 0x11
Solution for '0x13cd3L': 0x355D8 0x11
...
在这个样本中,每个调用都被脚本成功解析了
额外的,我们可以利用这些解析出来的解来运行miasm沙盒,从而获取解密后的字符串,一下是附加代码:
from miasm2.analysis.sandbox import Sandbox_Win_x86_64
from miasm2.os_dep.win_api_x86_32 import winobjs
...
parser = Sandbox_Win_x86_64.parser(description="PE sandboxer")
parser.add_argument("filename", help="PE Filename")
options = parser.parse_args()
options.jitter="gcc"
sb = Sandbox_Win_x86_64(options.filename, options, globals())
alloc_addr = winobjs.heap.alloc(sb.jitter, 0x1000)
def run_func_args(dec_addr, addr, l):
sb.jitter.vm.set_exception(0)
sb.jitter.vm.set_mem(alloc_addr, "\x00"*0x1000)
# 设置参数
sb.jitter.cpu.R8 = l
sb.jitter.cpu.RDX = addr
sb.jitter.cpu.RCX = alloc_addr
sb.jitter.push_uint64_t(0x1337beef)
# 运行
sb.run(dec_addr)
str_dec = sb.jitter.vm.get_mem(alloc_addr, l)
# 快速简单的编码检测
if len(str_dec) > 1 and str_dec[1] == "\x00":
s = sb.jitter.get_str_unic(alloc_addr)
else:
s = sb.jitter.get_str_ansi(alloc_addr)
print repr(s)
return str_dec
输出结果:
Solution for '0x13180L': 0x35338 0x14
'NDISWANIP'
Solution for '0x13c2eL': 0x355D8 0x11
'\r\n Adapter: '
...
Solution for '0x16191L': 0x35940 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
...
你还可以添加一些代码,用这些刚解密出来的字符串在ida数据库中添加注释:
conn.modules.idc.MakeComm(ref.frm, "DEC: %r" % str_dec)
Rpyc服务端脚本:ida_rpyc.py(在ida内运行)
最终脚本见此处:depgraph_find_args_run.py(在ida外运行)
展示2:追踪栈上参数
二进制文件ntevt.sys本质上应该是ntevtx64.sys的驱动程序,但是是32位版本的。解密函数同样存在,这是一个调用示例:
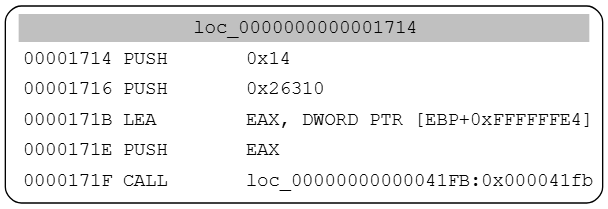
如前文,DepGraph算法追踪一个或多个表达式,问题在于,当你将原生代码翻译成ir时,内存访问式保持不变,但栈指针(Stack Pointer)是在不断变化的,原生代码示例:
及对应的ir
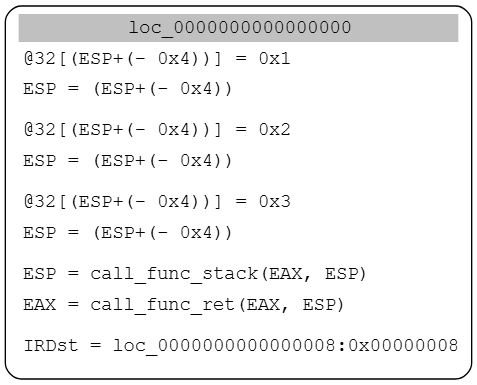
请注意这里对@32[ESP-4]的多次写入。如果你想追踪内存中的值,首先必须解析它们的指针。一旦每个内存指针都被解析(不太容易),你才能开始执行内存分析,在本例中,必须将ESP替换为某种形式,以便DepGraph算法能够意识到每个栈参数其实是不同的
简单的解决方案:我们将根据函数入口处的ESP值(即ESP_init)及其相对于该值的当前偏移量来表示ESP。我们可以把ida当作一个“先知(oracle)”,通过调用GetSpd来提供此偏移量。
为此,我们将创建一个IRA子类,在原生代码向IR翻译的过程中应用这一修改
class ira_fix_stk(machine.ira):
def gen_stk_update(self, instr):
"""
利用 IDA 作为启发式工具,获取 ESP 相对于 ESP_init 的偏移量
"""
stk_off = ExprInt(conn.modules.idc.GetSpd(instr.offset + 0x10000), self.sp.size)
return machine.mn.regs.regs_init[self.sp] + stk_off
def fix_assignblk_stack(self, assignblk, stk_high):
"""
将对 ESP 的访问替换为相对于 ESP_init 的相对值
"""
for dst, src in assignblk.items():
del(assignblk[dst])
stk_info = {self.sp: stk_high}
src = expr_simp(src.replace_expr(stk_info))
if dst != self.sp:
dst = expr_simp(dst.replace_expr(stk_info))
assignblk[dst] = src
def add_instr_to_irblock(self, block, instr, irb_cur, ir_blocks_all, gen_pc_updt):
"""
快速且简单的 ESP 修正实现
"""
irb_cur = self.pre_add_instr(block, instr, irb_cur, ir_blocks_all, gen_pc_updt)
if irb_cur is None:
return None
assignblk, ir_blocs_extra = self.instr2ir(instr)
if gen_pc_updt is not False:
self.gen_pc_update(irb_cur, instr)
# 获取修正后的栈值并应用
stk_high = self.gen_stk_update(instr)
self.fix_assignblk_stack(assignblk, stk_high)
irb_cur.irs.append(assignblk)
irb_cur.lines.append(instr)
if ir_blocs_extra:
for b in ir_blocs_extra:
b.lines = [instr] * len(b.irs)
ir_blocks_all += ir_blocs_extra
irb_cur = None
return irb_cur
这段代码只是一个粗糙解决,没有修复所有赋值块(Assign blocks),但目前而言有效,结果如下

现在该如何运行DepGraph?
- 获取调用行(Call line)
- 获取ESP的值,该值相对于其初始值,再加上IDA提供的偏移量
- 对获取到的第二和第三个参数运行DepGraph分析
在当前例子中,当前的ESP为ESP_init + 0xFFFFFFC8,因此我们将对变量组(@32[ESP_init+0xFFFFFFCC], @32[ESP_init+0xFFFFFFD0])运行依赖图分析,这将得到唯一解(0x26310, 0x14)
如果你记得修正run_func_args脚本,使其将参数推入栈中(而不是使用寄存器),并强制使用32位沙盒,那么所有的字符串都会被成功解析,你应该会得到如下结果
Solution for '0x1171fL': 0x26310 0x14
'NDISWANIP'
Solution for '0x11f24L': 0x26580 0x11
'\r\n Adapter: '
...
Solution for '0x13b9fL': 0x268B8 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
...
这些字符串与64位驱动程序中完全一致,在elfesteem的帮助下,我们可以添加一个新区段并对二进制文件进行补丁,使字符串以明文形式显示,并让代码中的引用直接指向它们。
这是一个使用miasm的depgraph ida脚本的演示,在这个例子中,我们将追踪dec_str函数调用的第一个参数,由于本例中的参数使通过栈传递的,我们需要选择追踪内存变量,并使用来自ida的反别名(un-alias)启发式方法(按下Shif+N来切换到下一个解)
动图不插了
结论
在本博文中,我们使用了依赖图(Dependency Graph)算法来获取Equation Group恶意软件中的加密字符串。该算法在经典案例(栈、寄存器参数等)中表现良好。
一个关键点是,即使在复杂的情况下(如嵌套循环等),我们仍然可以获得依赖关系图,它可以用于范围分析(Range analysis)或其他算法。当需要计算最终值时,算法能够根据循环依赖情况告知该结果是否可信。
下一篇直接看源码吧,之后再总结剩下的特性








