
ELF
比起PE,ELF分了section给编译器和segment给加载器,处理外部函数的时候调用了GOT/PLT(延迟绑定),PE则用的IAT
elf格式由system v标准定义,设计更灵活,支持可执行文件,共享库,目标文件等多种类型
常见使用场景,可执行文件, 当运行Linux Shell上的各种命令时(ls, grep) 时, 都是执行的ELF格式的文件. 其包含程序的机器代码和必要的元数据, 定义入口点、程序头表等执行所需信息, 加载器(loader)能直接将其映射到内存并执行.
常见后缀
- 无后缀或.bin,可执行文件如/bin/ls、/usr/bin/python3,通常无后缀
- .so,动态库/共享库,共享对象,类似windows的dll,提供动态链接功能(允许多个程序共享同一份代码,节省内存,程序运行时才加载所需库)
补:
动态库和共享库本质是同一个东西,例如在windows下的.dll动态链接库 - .a,静态链接库,包含多个目标文件(.o)归档集合,编译时会被完整嵌入可执行文件,在链接时相关代码会被直接将复制到最终的可执行文件中,因此部署更简单,不依赖外部库
- .o,目标文件,编译器输出的中间文件(编译但未链接,包含编译后的机器代码,但不能直接执行),保存了符号表,重定位信息等待链接器处理,要链接器处理后生成可执行文件Dynamic Link Library,在linux/unix下的.so共享对象(shared object)链接器最终将多个.o文件合并为可执行文件或共享库,目标文件允许分离编译,提高大型项目的效率
- .ko,内核模块,linux内核的驱动程序,运行于内核空间,相当于window里面的.sys(驱动程序),运行在ring 0(最高权限),比起普通elf,ko驱动没有main,只有module_init()(插入模块时执行)和对应的exit,会看到大量重定位表,因为要被“链接”进内核
- .mod,部分系统的模块文件,如早期unix功能类似ko,包含了模块的版本信息(Version Magic)和符号依赖关系。
- coredump内存转储文件:系统崩溃或程序异常终止时生成的调试信息,记录程序崩溃时的内存状态,寄存器值等信息
数据形式
ELF文件格式支持8位/32位体系结构。当然,这种格式是可以扩展的,也可以支持更小的或者更大位数的处理器架构。因此,目标文件会包含一些控制数据,这部分数据表明了目标文件所使用的架构,这也使得它可以被通用的方式来识别和解释。目标文件中的其它数据采用目的处理器的格式进行编码,与在何种机器上创建没有关系。这里其实想表明的意思目标文件可以进行交叉编译,我们可以在x86平台生成arm平台的可执行代码
目标文件中的所有数据结构都遵从“自然”大小和对齐规则。如下
| 名称 | 长度 | 对齐方式 | 用途 |
|---|---|---|---|
| Elf32_Addr | 4 | 4 | 无符号程序地址 |
| Elf32_Half | 2 | 2 | 无符号半整型 |
| Elf32_Off | 4 | 4 | 无符号文件偏移 |
| Elf32_Sword | 4 | 4 | 有符号大整型 |
| Elf32_Word | 4 | 4 | 无符号大整型 |
| unsigned char | 1 | 1 | 无符号小整型 |
如果必要,数据结构可以包含显式地补齐来确保4字节对象按4字节对齐,强制数据结构的大小是4的整数倍等等。数据同样适用是对齐的。因此,包含一个Elf32_Addr类型成员的结构体会在文件中的4字节边界处对齐。
为了具有可移植性,ELF文件不使用位域。
结构
| 区域位置 | 组件名称 (中文) | 英文对应 | 说明 |
|---|---|---|---|
| 顶部 | ELF 文件头 | ELF Header | 文件的总索引,包含魔数、版本等。 |
| 上部 | 程序头部表 | Program Header Table | 描述段(Segment)信息,用于执行视图。 |
| 中部 | .text | Code Section | 代码节(指令)。 |
| 中部 | .data | Data Section | 数据节(已初始化全局变量)。 |
| 中部 | .bss | BSS Section | 未初始化数据节。 |
| 中部 | .symtab | Symbol Table | 符号表(函数名、变量名)。 |
| 中部 | .debug | Debug Info | 调试信息。 |
| 中部 | .line | Line Number Table | 行号表(源码行号对应)。 |
| 中部 | … | Others | 其他各类节。 |
| 底部 | 节区头部表 | Section Header Table | 描述节(Section)信息,链接视图的核心,记录了上面所有节的位置。 |
ELF头部
文件起始位置,固定大小(32位为52字节,64位位64字节)
结构体
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT]; // ELF标识符
Elf32_Half e_type; // 文件类型
Elf32_Half e_machine; // 目标架构
Elf32_Word e_version; // ELF版本
Elf32_Addr e_entry; // 程序入口点
Elf32_Off e_phoff; // 程序头表偏移
Elf32_Off e_shoff; // 节头表偏移
Elf32_Word e_flags; // 处理器特定标志
Elf32_Half e_ehsize; // ELF头部大小
Elf32_Half e_phentsize; // 程序头表项大小
Elf32_Half e_phnum; // 程序头表项数量
Elf32_Half e_shentsize; // 节头表项大小
Elf32_Half e_shnum; // 节头表项数量
Elf32_Half e_shstrndx; // 节名称字符串表索引
} Elf32_Ehdr;
其中,e_ident字段的前4个字节固定为0x7f、’E’、’L’、’F’,这是ELF文件的魔数标识。ascll码(45 4C 46)
e_ident
ELF提供了一个目标文件框架,以便于支持多种处理器,多种编码格式的机器。该变量给出了用于解码和解释文件中与机器无关的数据的方式。这个数组对于不同的下标的含义如下
| 宏名称 | 下标 | 目的 |
|---|---|---|
| EI_MAG0 | 0 | 文件标识 |
| EI_MAG1 | 1 | 文件标识 |
| EI_MAG2 | 2 | 文件标识 |
| EI_MAG3 | 3 | 文件标识 |
| EI_CLASS | 4 | 文件类 |
| EI_DATA | 5 | 数据编码 |
| EI_VERSION | 6 | 文件版本 |
| EI_PAD | 7 | 补齐字节开始处 |
e_ident[EI_MAG0]到e_ident[EI_MAG3],即文件的头4个字节,被称作“魔数”,标识该文件是一个ELF目标文件,在ASCII码表中,0x7f的含义是DEL(删除控制符) 。这是一个不可打印的控制字符。
使用0x7f的原因有一是为了区分脚本与二进制: Linux/Unix 中有很多以文本形式存在的可执行脚本(比如Shell或Python),它们大部分以可打印字符 #!(Shebang)开头。而ELF文件作为纯粹的二进制文件,用0x7f开头可以瞬间与脚本区分开来。
| 名称 | 值 | 位置 |
|---|---|---|
| ELFMAG0 | 0x7f | e_ident[EI_MAG0] |
| ELFMAG1 | ‘E’ | e_ident[EI_MAG1] |
| ELFMAG2 | ‘L’ | e_ident[EI_MAG2] |
| ELFMAG3 | ‘F’ | e_ident[EI_MAG3] |
e_ident[EI_CLASS] 为 e_ident[EI_MAG3]的下一个字节,标识文件的类型或容量。
| 名称 | 值 | 意义 |
|---|---|---|
| ELFCLASSNONE | 0 | 无效类型 |
| ELFCLASS32 | 1 | 32位文件 |
| ELFCLASS64 | 2 | 64位文件 |
ELF文件的设计使得它可以在多种字节长度的机器之间移植,而不需要强制规定机器的最长字节长度和最短字节长度。ELFCLASS32类型支持文件大小和虚拟地址空间上限为4GB的机器;它使用上述定义中的基本类型。
ELFCLASS64类型用于64位架构。
e_ident[EI_DATA]字节给出了目标文件中的特定处理器数据的编码方式。下面是目前已定义的编码
| 名称 | 值 | 意义 |
|---|---|---|
| ELFDATANONE | 0 | 无效数据编码 |
| ELFDATA2LSB | 1 | 小端 |
| ELFDATA2MSB | 2 | 大端 |
其它值被保留,在未来必要时将被赋予新的编码。
文件数据编码方式表明了文件内容的解析方式。正如之前所述,ELFCLASS32类型文件使用了具有1,2和4字节的变量类型。对于已定义的不同的编码方式,其表示如下所示,其中字节号在左上角。
ELFDATA2LSB编码使用补码,最低有效位(Least Significant Byte)占用最低地址
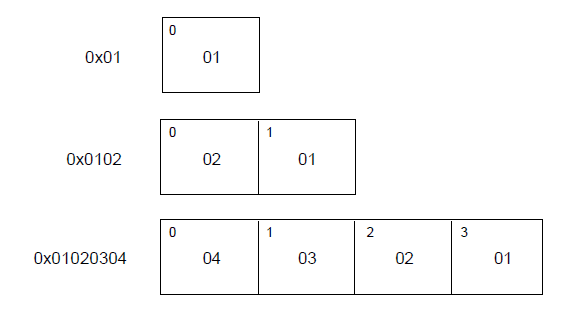
ELFDATA2MSB编码使用补码,最高有效位(Most Significant Byte)占用最低地址
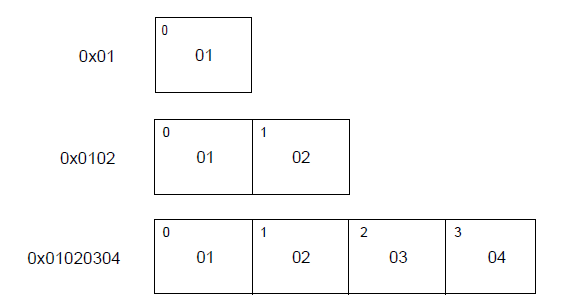
e_ident[EI_DATA] 给出了ELF头的版本号。目前这个值必须是EV_CURRENT,即之前已经给出的e_version。
e_ident[EI_PAD] 给出了 e_ident 中未使用字节的开始地址。这些字节被保留并置为0;处理目标文件的程序应该忽略它们。如果之后这些字节被使用,EI_PAD的值就会改变。
补:
ELF 文件头用于描述整个文件的整体结构和基本属性。字段命名有着明显的缩写规律,通常:
ph= Program Header (程序头部表,描述运行时内存布局)sh= Section Header (节区头部表,描述链接时的数据区块)ent= Entry (表项)num= Number (数量)off= Offset (偏移量)
e_type
标识目标文件的具体类型。
| 名称 | 值 | 含义 | 解释 |
|---|---|---|---|
| ET_NONE | 0 | 未知类型 | 未确定的文件格式 |
| ET_REL | 1 | 可重定位文件 (.o) | 供链接器使用的目标文件,如 gcc -c 编译产物 |
| ET_EXEC | 2 | 可执行文件 | 可以直接投入内存运行的独立程序 |
| ET_DYN | 3 | 共享目标文件 (.so) | 动态链接库,在运行时与其他文件一起被加载 |
| ET_CORE | 4 | 核心转储文件 | 程序崩溃时的内存镜像 (Core Dump) |
| ET_LOPROC~HIPROC | 0xff00~0xffff | 处理器保留区间 | 预留给特定平台自定义类型 |
e_machine
指定该文件兼容的硬件架构平台。通常以 EM_ (ELF Machine) 开头。
- 常用的如:EM_386 (Intel x86, 值:3)、EM_MIPS (值:8)、EM_SPARC (值:2) 等。
- 补: 针对特定平台的特有标志,其命名通常带有
EF_<架构>_前缀(如EF_MIPS_NOREORDER)。
e_version
ELF 文件的格式版本。
- EV_CURRENT (1):目前的默认版本号。(虽然 ELF 有扩展,但底层版本号大多保持为 1)。
入口与全局偏移量
| 字段名 | 全称提示 | 说明 | 核心重点 |
|---|---|---|---|
| e_entry | Entry Point | 执行入口地址 | 操作系统将控制权交给程序的初始虚拟地址。动态库或不直接执行的文件通常为 0。 |
| e_phoff | Program Header Offset | 程序头部表偏移 | 程序头表在文件中的起始位置(字节单位)。无则为 0。 |
| e_shoff | Section Header Offset | 节区头部表偏移 | 节区头表在文件中的起始位置(字节单位)。无则为 0。 |
大小与数量描述 (表结构信息)
这部分字段用于描述 ELF 文件中各大表格占据的内存大小。遵循公式:总长度 = 表项大小 (entsize) × 表项数量 (num)。
| 字段名 | 全称提示 | 说明 |
|---|---|---|
| e_ehsize | ELF Header Size | ELF文件头自身的字节大小。 |
| e_flags | ELF Flags | 处理器特定标志位。 |
| e_phentsize | Program Header Entry Size | 程序头部表中,单个表项的大小。 |
| e_phnum | Program Header Number | 程序头表项的数量。(e_phentsize × e_phnum = 程序头表总大小) |
| e_shentsize | Section Header Entry Size | 节区头部表中,单个表项的大小。 |
| e_shnum | Section Header Number | 节头表项的数量。(e_shentsize × e_shnum = 节区头表总大小) |
| e_shstrndx | Section Header String Table Index | 节区名称字符串表的索引。指向节区头部表中专门用于存储节名(如 .text、.data)字符串的那一个表项位置。如果不含该表,则值为 SHN_UNDEF。 |
补:e_ph 是一组(负责程序的内存加载),e_sh 是一组(负责节区的链接划分),和off(偏移)、entsize(单项大小)、num(数量)
文件类型Type
elf文件文件主要有四种类型
可重定位文件ET_REL,可执行文件ET_EXEC,共享目标文件ET_DYN,核心转储文件ET_CORE。但我们使用g++生成的是一个DYN类型的文件,括号里进一步说明这是一个PIE程序,这不是一个传统的EXEC类型的可执行文件,这是由于安全考虑的演进结果
问题:传统上,可执行文件是EXEC类型,他们有固定的加载地址,但随着安全威胁到增加,尤其是缓冲区溢出和返回导向编程(ROP)攻击,操作系统引入了aslr作为防御机制,但aslr最初只能随机化共享库和堆栈的位置,而传统EXEC类型的可执行文件主体依然加载在固定地址,成为攻击者目标。为了解决这个问题,PLE(文件无关可执行文件)被开发,允许整个程序(包括代码段)被随机加载
原理:当g++生成PIE可执行文件时,其使用相对寻址而非绝对寻址,编译所有代码为位置无关代码(PIC),并将可执行文件标记为DYN类型
程序加载:操作系统加载器看到DYN类型的可执行文件时,会将其当作共享库一样处理,随机选择一个基地址,然后相应调整所有内部引用,这种行为很像动态库,因此这些文件被标记为DYN类型,尽管它们实际上是可执行文件
使用g++ -no-pie选项进行编译程序即可编译一个传统的EXEC类型可执行文件
- 兼容性相关字段包括Machine目标架构,Class类别,Data数据编码等
- 该ELF文件结构相关字段,包括程序头表,节头表偏移量,长度与数量等
程序头表(Program Header Table)
如果程序头部表(Program Header Table)存在的话, 它会告诉系统如何创建进程. 用于生成进程的目标文件必须具有程序头部表, 但是重定位文件不需要这个表.
描述段(segment)信息,用于程序加载和执行
结构体
typedef struct {
Elf32_Word p_type; // 段类型,或表明该结构的相关信息
Elf32_Off p_offset; // 段在文件中的偏移
Elf32_Addr p_vaddr; // 该段第一个字节在内存中的虚拟地址
Elf32_Addr p_paddr; // 物理地址(通常与虚拟地址相同)
Elf32_Word p_filesz; // 段在文件镜像中段的大小
Elf32_Word p_memsz; // 段在内存镜像中段的大小
Elf32_Word p_flags; // 段标志(读/写/执行)
Elf32_Word p_align; // 段对齐方式
} Elf32_Phdr;
段类型
段的类型p_type如下表所示
程序头部表中的段类型又可以分为基本段和扩展段两大类
- 基本段:基本段是ELF规范最初定义的标准段类型,在所有符合ELF标准的系统中都被支持和识别,这些段类型构成了ELF可执行文件的基础结构,对于程序的加载和执行是必不可少的,基本段剋行通常具有较小的类型值(0-7)并在原始ELF规范中明确定义
- 扩展段:扩展段是在ELF基本规范之外,由特定操作系统,编译器,或工具链引入的额外段类型,这些段类型通常用于实现特定于平台的功能,安全特性,或性能优化
| 段类型 | 值 | 描述 | 用途 |
|---|---|---|---|
| PT_NULL | 0 | 未使用段 | 表示一个未使用的程序头部表项,系统会忽略该段 |
| PT_LOAD | 1 | 可加载段 | 定义需要从文件映射到内存中的段,包含代码(.text)和数据(.data)等 |
| PT_DYNAMIC | 2 | 动态链接信息段 | 包含动态链接器所需的信息,如共享库依赖、符号表位置等 |
| PT_INTERP | 3 | 解释器段 | 包含程序解释器路径的字符串,通常指向动态链接器,如”/lib/ld-linux.so.2″ |
| PT_NOTE | 4 | 附加信息段 | 存储辅助信息,如版本、供应商信息、ABI 兼容性说明等 |
| PT_SHLIB | 5 | 保留段 | 在当前 ELF 规范中未定义用途,保留供将来使用 |
| PT_PHDR | 6 | 程序头部表段 | 包含程序头部表自身在内存中的位置和大小信息 |
| PT_TLS | 7 | 线程局部存储段 | 包含线程局部变量的初始值和模板,用于线程专有数据 |
| PT_GNU_EH_FRAME | 0x6474e550 | 异常处理框架段 | GNU 特有段类型,包含用于栈展开的异常处理信息 |
| PT_GNU_STACK | 0x6474e551 | 栈权限段 | GNU 扩展,用于标记程序栈是否具有可执行权限 |
| PT_GNU_RELRO | 0x6474e552 | 只读重定位段 | GNU 扩展,标记在初始化后应设为只读的段,增强安全性 |
| PT_LOPROC | 0x70000000 | 处理器特定段下限 | 为处理器特定语义保留的段类型范围的下界 |
| PT_HIPROC | 0x7fffffff | 处理器特定段上限 | 为处理器特定语义保留的段类型范围的上界 |
段地址
ELF文件中程序段的p_vaddr表示该段在虚拟内存中的预期加载地址,但这个地址通常不是最终的实际加载地址,而是需要与基地址结合计算
在讨论一个可执行程序实际的虚拟地址之前,需要首先明确是否使用了PIC位置无关代码技术:
- 对于那些使用绝对地址的代码,程序在编译和链接时,就假定它将在特定的虚拟地址空间中运行,加载器也会尝试将程序段放置在它们指定的虚拟地址上
- 但对于可能被加载到任意位置的共享库或者时PIC/PLE程序而言,其完全避免了绝对地址引用,而是通过相对寻址的方式来访问自己的代码和数据,使用了全局偏移表(GOT)和过程链接表(PLT)处理动态符号。段和段之间维持着相对位置关系即可
程序段在内存中实际地址的计算公式
实际加载地址 = 基地址 + (p_vaddr - 最小可加载段的p_vaddr)
基地址由动态加载器(如ld.so)在加载时决定,还会受到ASLR,页对齐等机制的影响
段标志位
当系统为可加载的段创建
内存镜像时,它会按照p_flags将段设置为对应的权限
| 值 | 名称 | 含义 |
|---|---|---|
| 0x1 | PF_X | 可执行段(Executable segment) |
| 0x2 | PF_W | 可写段(Writeable segment) |
| 0x4 | PF_R | 可读段(Readable segment) |
节头表(Section Header Table)
描述节的信息(section),主要用于链接和调试
typedef struct {
Elf32_Word sh_name; // 节名称(字符串表索引)
Elf32_Word sh_type; // 节类型
Elf32_Word sh_flags; // 节标志
Elf32_Addr sh_addr; // 节在内存中的地址
Elf32_Off sh_offset; // 节在文件中的偏移
Elf32_Word sh_size; // 节大小
Elf32_Word sh_link; // 链接到其他节的索引
Elf32_Word sh_info; // 附加信息
Elf32_Word sh_addralign; // 节对齐方式
Elf32_Word sh_entsize; // 条目大小(如果有)
} Elf32_Shdr;
| 成员 | 说明 |
|---|---|
| sh_name | 节名称,本质是一个数值,作为节区头字符串表节区 (Section Header String Table Section) 的索引,在该表中是一个以 NULL 结尾的字符串 |
| sh_type | 节区类型 |
| sh_flags | 每一 bit 代表不同的标志,描述节是否可写、可执行、需要分配内存等属性 |
| sh_addr | 如果节区将出现在进程的内存映像中,此成员给出节区的第一个字节应该在进程镜像中的位置。否则,此字段为 0 |
| sh_offset | 给出节区的第一个字节与文件开始处之间的偏移。SHT_NOBITS 类型的节区不占用文件的空间,因此其 sh_offset 成员给出的是概念性的偏移 |
| sh_size | 此成员给出节区的字节大小。除非节区的类型是 SHT_NOBITS,否则该节占用文件中的 sh_size 字节。类型为 SHT_NOBITS 的节区长度可能非零,不过却不占用文件中的空间 |
| sh_link | 此成员给出节区头部表索引链接,其具体的解释依赖于节区类型 |
| sh_info | 此成员给出附加信息,其解释依赖于节区类型 |
| sh_addralign | 某些节区的地址需要对齐。目前它仅允许为 0 以及 2 的正整数幂数,0 和 1 表示没有对齐约束 |
| sh_entsize | 某些节区中存在具有固定大小的表项的表,如符号表。对于这类节区,该成员给出每个表项的字节大小。反之,此成员取值为 0 |
节区头部表中存在一些特殊的节区,如:
- SHN_UNDEF(0),表示未定义的节区
- SHN_LORESERVE(0xFF00),表示保留区的下界,SHN_HIRESERVE(0xFFFF),表示保留区的上界
系统保留在SHN_LORESERVE到SHN_HIRESERVE之间(包含边界)的索引值,这些值不在节头表中引用,节头表不包含保留索引项
节区类型
| 名称 | 取值 | 说明 |
|---|---|---|
| SHT_NULL | 0 | 该类型节区是非活动的, 这种类型的节头中的其它成员取值无意义. |
| SHT_PROGBITS | 1 | 该类型节区包含程序定义的信息, 它的格式和含义都由程序来决定. |
| SHT_SYMTAB | 2 | 该类型节区包含一个符号表(SYMbol TABle). 目前目标文件对每种类型的节区都只能包含一个, 不过这个限制将来可能发生变化. 一般, SHT_SYMTAB 节区提供用于链接编辑(指 ld 而言)的符号, 尽管也可用来实现动态链接. |
| SHT_STRTAB | 3 | 该类型节区包含字符串表(STRing TABle). |
| SHT_RELA | 4 | 该类型节区包含显式指定位数的重定位项(RELocation entry with Addends), 例如, 32 位目标文件中的 Elf32_Rela 类型. 此外, 目标文件可能拥有多个重定位节区. |
| SHT_HASH | 5 | 该类型节区包含符号哈希表(HASH table). |
| SHT_DYNAMIC | 6 | 该类型节区包含动态链接的信息(DYNAMIC linking). |
| SHT_NOTE | 7 | 该类型节区包含以某种方式标记文件的信息(NOTE). |
| SHT_NOBITS | 8 | 该类型节区不占用文件的空间, 其它方面和SHT_PROGBITS相似. 尽管该类型节区不包含任何字节, 其对应的节头成员sh_offset 中还是会包含概念性的文件偏移. |
| SHT_REL | 9 | 该类型节区包含重定位表项(RELocation entry without Addends), 不过并没有指定位数. 例如, 32位目标文件中的 Elf32_rel 类型. 目标文件中可以拥有多个重定位节区. |
| SHT_SHLIB | 10 | 该类型此节区被保留, 不过其语义尚未被定义. |
| SHT_DYNSYM | 11 | 作为一个完整的符号表, 它可能包含很多对动态链接而言不必要的符号. 因此, 目标文件也可以包含一个 SHT_DYNSYM 节区, 其中保存动态链接符号的一个最小集合, 以节省空间. |
| SHT_LOPROC | 0X70000000 | 此值指定保留给处理器专用语义的下界(LOw PROCessor-specific semantics). |
| SHT_HIPROC | 0X7FFFFFFF | 此值指定保留给处理器专用语义的上界(HIgh PROCessor-specific semantics). |
| SHT_LOUSER | 0X80000000 | 此值指定保留给应用程序的索引下界. |
| SHT_HIUSER | 0X8FFFFFFF | 此值指定保留给应用程序的索引上界. |
节区标志位
节头中sh_flags字段的每一个比特位都可以给出其相应的标记信息, 其定义了对应的节区的内容是否可以被修改、被执行等信息.
| 名称 | 值 | 说明 |
|---|---|---|
| SHF_WRITE | 0x1 | 这种节包含了进程运行过程中可以被写的数据. |
| SHF_ALLOC | 0x2 | 这种节在进程运行时占用内存. 对于不占用目标文件的内存镜像空间的某些控制节, 该属性处于关闭状态(off). |
| SHF_EXECINSTR | 0x4 | 这种节包含可执行的机器指令(EXECutable INSTRuction). |
| SHF_MASKPROC | 0xf0000000 | 所有在这个掩码中的比特位用于特定处理器语义. |
link与info字段
当节区类型的不同的时候,sh_link和sh_info也会具有不同的含义
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_DYNAMIC | 节区中使用的字符串表的节头索引 | 0 |
| SHT_HASH | 此哈希表所使用的符号表的节头索引 | 0 |
| SHT_REL/SHT_RELA | 与符号表相关的的节头索引 | 重定位应用到的节的节头索引 |
| SHT_SYMTAB/SHT_DYNSYM | 操作系统特定信息, Linux 中的 ELF 文件中该项指向符号表中符号所对应的字符串节区在 Section Header Table 中的偏移. | 操作系统特定信息 |
| other | SHN_UNDEF | 0 |
节区
节存储实际内容,常见节有:
- .text:可执行代码
- .data:已初始化的全局变量
- .bss:未初始化的全局变量(不占用文件空间)
- .rodata:只读数据
- .symtab:符号表
- .strtab:字符串表
- .rel.*:重定位信息
- .dynamic:动态链接信息
- .interp:程序解释器路径(如/lib/ld-linux.so.2)
| 名称 | 类型 | 属性 | 含义 |
|---|---|---|---|
| .bss | SHT_NOBITS | SHF_ALLOC + SHF_WRITE | 包含将出现在程序的内存映像中的为初始化数据。根据定义,当程序开始执行,系统将把这些数据初始化为 0。此节区不占用文件空间。 |
| .comment | SHT_PROGBITS | (无) | 包含版本控制信息。 |
| .data | SHT_PROGBITS | SHF_ALLOC + SHF_WRITE | 这些节区包含初始化了的数据,将出现在程序的内存映像中。 |
| .data1 | SHT_PROGBITS | SHF_ALLOC + SHF_WRITE | 这些节区包含初始化了的数据,将出现在程序的内存映像中。 |
| .debug | SHT_PROGBITS | (无) | 此节区包含用于符号调试的信息。 |
| .dynamic | SHT_DYNAMIC | SHF_ALLOC 位,是否 SHF_WRITE 位被设置取决于处理器。 | 此节区包含动态链接信息。节区的属性将包含 SHF_ALLOC 位。 |
| .dynstr | SHT_STRTAB | SHF_ALLOC | 此节区包含用于动态链接的字符串,大多数情况下这些字符串代表了与符号表项相关的名称。 |
| .dynsym | SHT_DYNSYM | SHF_ALLOC | 此节区包含了动态链接符号表。 |
| .fini | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR | 此节区包含了可执行的指令,是进程终止代码的一部分。程序正常退出时,系统将安排执行这里的代码。 |
| .got | SHT_PROGBITS | 此节区包含全局偏移表。 | |
| .hash | SHT_HASH | SHF_ALLOC | 此节区包含了一个符号哈希表。 |
| .init | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR | 此节区包含了可执行指令,是进程初始化代码的一部分。当程序开始执行时,系统要在开始调用主入口之前(通常指 C 语言的 main 函数)执行这些代码。 |
| .interp | SHT_PROGBITS | 此节区包含程序解释器的路径名。如果程序包含一个可加载的段,段中包含此节区,那么节区的属性将包含 SHF_ALLOC 位,否则该位为 0。 | |
| .line | SHT_PROGBITS | (无) | 此节区包含符号调试的行号信息,其中描述了源程序与机器指令之间的对应关系。其内容是未定义的。 |
| .note | SHT_NOTE | (无) | 此节区中包含注释信息,有独立的格式。 |
| .plt | SHT_PROGBITS | 此节区包含过程链接表(procedure linkage table)。 | |
| .rel[name] | SHT_REL | 这些节区中包含了重定位信息。如果文件中包含可加载的段,段中有重定位内容,节区的属性将包含 SHF_ALLOC 位,否则该位置 0。传统上 name 根据重定位所适用的节区给定。例如 .text 节区的重定位节区名字将是:.rel.text 或者 .rela.text。 | |
| .rela[name] | SHT_RELA | 这些节区中包含了重定位信息。如果文件中包含可加载的段,段中有重定位内容,节区的属性将包含 SHF_ALLOC 位,否则该位置 0。 | |
| .rodata | SHT_PROGBITS | SHF_ALLOC | 这些节区包含只读数据,这些数据通常参与进程映像的不可写段。 |
| .rodata1 | SHT_PROGBITS | SHF_ALLOC | 这些节区包含只读数据,这些数据通常参与进程映像的不可写段。 |
| .shstrtab | SHT_STRTAB | 此节区包含节区名称。 | |
| .strtab | SHT_STRTAB | 此节区包含字符串,通常是代表与符号表项相关的名称。如果文件拥有一个可加载的段,段中包含符号串表,节区的属性将包含 SHF_ALLOC 位,否则该位为 0。 | |
| .symtab | SHT_SYMTAB | 此节区包含一个符号表。如果文件中包含一个可加载的段,并且该段中包含符号表,那么节区的属性中包含SHF_ALLOC 位,否则该位置为 0。 | |
| .text | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR | 此节区包含程序的可执行指令。 |
段
段(Segments)是ELF文件在执行视图(Execution View)中的基本单位, 与链接视图中的节(Sections)不同, 段是程序加载到内存时实际使用的单位.
链接视图的节(Sections)提供了非常细粒度的程序组织方式, 这对编译器和链接器很有用. 但对操作系统加载器来说, 处理大量节会增加复杂性并降低效率. 段提供了一种更高层次的抽象, 将具有相似属性(如内存权限)的多个节组合在一起, 简化了加载过程.
一个简单elf可执行文件内存布局如下
虚拟地址空间
+------------------+ 高地址
| 栈区域 |
| ↓ |
| |
| ↑ |
| 堆区域 |
+------------------+
| 未映射区域 |
+------------------+
| |
| 数据段(rw-) | ← 包含.data, .bss等节
| |
+------------------+
| |
| 代码段(r-x) | ← 包含.text, .rodata等节
| |
+------------------+ 低地址
节区类型
字符串表节区
对于字符串表类型SHT_STRTAB来说,其包含了以NULL(0)结尾的字符串序列,对字符串的引用通常以字符串在表中的下标来给出,例如节区头表的sh_name,便是使用这种方式来给出自身的名字,节区头表关联的时.shstrtab节(Section Header String Table)
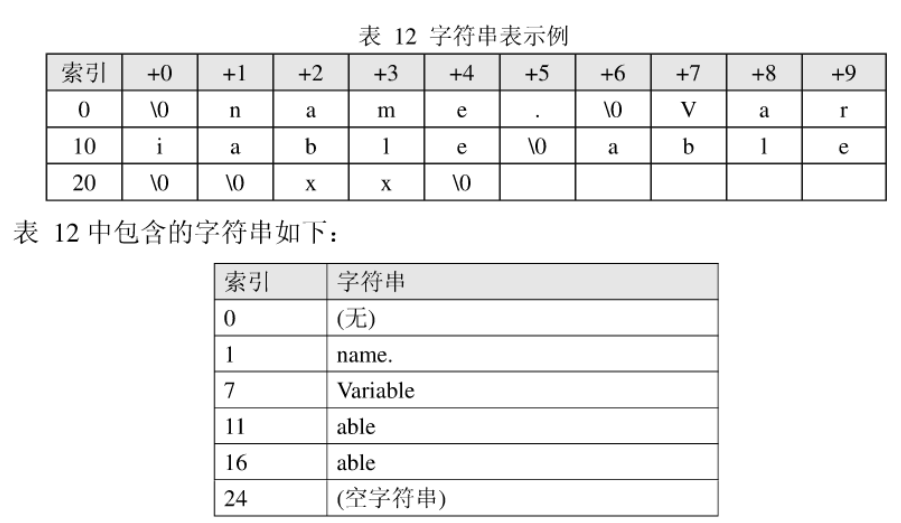
符号表节区
对于符号表类型SHT_SYMTAB, 其包含了用来定位、重定位程序中符号定义和引用的信息, 表项字段含义如下
| 字段 | 说明 |
|---|---|
| st_name | 符号在字符串表中对应的索引. 如果该值非 0, 则它表示了给出符号名的字符串表索引, 否则符号表项没有名称. 注: 外部 C 符号在 C 语言和目标文件的符号表中具有相同的名称. |
| st_value | 给出与符号相关联的数值, 具体取值依赖于上下文, 可能是一个正常的数值、一个地址等等. |
| st_size | 给出对应符号所占用的大小. 如果符号没有大小或者大小未知, 则此成员为0. |
| st_info | 给出符号的类型和绑定属性. 之后会给出若干取值和含义的绑定关系. |
| st_other | 目前为0, 其含义没有被定义. |
| st_shndx | 每个符号表项都以和其他节区间的关系给出定义, 此成员给出相关的节区头表索引 |
st_value
ELF规范中对于符号的寻址逻辑,对变量(OBJECT)和函数(FUNC)是一视同仁的。决定st_value真实含义的唯一标准是:当前ELF文件的类型(可重定位、可执行、共享库) 以及 该符号所处的特殊节区索引 (st_shndx)
st_value的含义由以下因素决定
- 文件类型(可重定位文件,可执行文件或共享对象文件)
- 符号绑定类型(局部,全局,弱符号)
- 在可重定位文件(.o文件), 对于所有已定义的符号(无论是变量还是函数), st_value都表示节区偏移量, 也就是相对于由st_shndx标识的节区起始位置的偏移量. 这一点对于变量和函数本质上是相同的
- 在可执行文件或共享对象文件中: 对于所有已定义的符号,st_value都表示虚拟内存地址
c代码演示
#include <stdio.h>
// 全局变量
int global_var = 42;
// 静态全局变量
static int static_global = 100;
// 函数声明
void another_function(void);
int main(void) {
int local_var = 10;
printf("全局变量: %d\n", global_var);
another_function();
return 0;
}
void another_function(void) {
printf("另一个函数被调用\n");
}
这边我们主要关注三个符号: 全局变量global_var, 静态全局变量static_global以及一个函数another_function
首先使用-c选项编译出来.o目标文件, 并查看其符号表以及节区头表
$ gcc -c symbols.c -o symbols.o
$ readelf -s symbols.o
Symbol table '.symtab' contains 10 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS symbols.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 .text
3: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 static_global
4: 0000000000000000 0 SECTION LOCAL DEFAULT 5 .rodata
5: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 global_var
6: 0000000000000000 55 FUNC GLOBAL DEFAULT 1 main
7: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
8: 0000000000000037 22 FUNC GLOBAL DEFAULT 1 another_function
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
$ readelf -S symbols.o
There are 14 section headers, starting at offset 0x3d8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
000000000000004d 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000002a0
0000000000000090 0000000000000018 I 11 1 8
[ 3] .data PROGBITS 0000000000000000 00000090
0000000000000008 0000000000000000 WA 0 0 4
...
通过查看节区头表, 可以看到索引Ndx 1, 3分别对应.text代码段以及.data数据段, 此时st_value表示该符号在对应的分区的偏移量,使用objdump进行验证
#################
## 查看数据段 ###
#################
$ objdump -s -j .data symbols.o
symbols.o: file format elf64-x86-64
Contents of section .data:
0000 2a000000 64000000 *...d...
#################
## 查看代码段 ###
#################
# 直接查看 .text 不够直观
$ objdump -s -j .text symbols.o
# 反汇编查看代码段
$ objdump -d symbols.o
symbols.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 0a 00 00 00 movl $0xa,-0x4(%rbp)
f: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 15 <main+0x15>
15: 89 c6 mov %eax,%esi
17: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 1e <main+0x1e>
1e: 48 89 c7 mov %rax,%rdi
21: b8 00 00 00 00 mov $0x0,%eax
26: e8 00 00 00 00 call 2b <main+0x2b>
2b: e8 00 00 00 00 call 30 <main+0x30>
30: b8 00 00 00 00 mov $0x0,%eax
35: c9 leave
36: c3 ret
0000000000000037 <another_function>:
37: 55 push %rbp
38: 48 89 e5 mov %rsp,%rbp
3b: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 42 <another_function+0xb>
42: 48 89 c7 mov %rax,%rdi
45: e8 00 00 00 00 call 4a <another_function+0x13>
4a: 90 nop
4b: 5d pop %rbp
4c: c3 ret
可以看到:
- 在.data中, 以小端序存放着42和100两个全局变量的值
- .text为汇编后的代码, 使用objdump -d查看反汇编后的代码, 可以看到在对应偏移量的位置为another_function
所以无论是函数还是变量, st_value都是对应节区的偏移量
下面分析可执行文件中的情况, 我们需要验证: st_value表示虚拟地址的位置
$ readelf -s symbols
...
Symbol table '.symtab' contains 28 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS symbols.c
2: 0000000000004024 4 OBJECT LOCAL DEFAULT 24 static_global
3: 0000000000000000 0 FILE LOCAL DEFAULT ABS
12: 0000000000001198 0 FUNC GLOBAL HIDDEN 15 _fini
13: 0000000000001180 22 FUNC GLOBAL DEFAULT 14 another_function
14: 0000000000000000 0 FUNC GLOBAL DEFAULT UND printf@GLIBC_2.2.5
15: 0000000000004020 4 OBJECT GLOBAL DEFAULT 24 global_var
16: 0000000000004010 0 NOTYPE GLOBAL DEFAULT 24 __data_start
...
$ readelf -S symbols
There are 30 section headers, starting at offset 0x3580:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[14] .text PROGBITS 0000000000001050 00001050
0000000000000146 0000000000000000 AX 0 0 16
[24] .data PROGBITS 0000000000004010 00003010
0000000000000018 0000000000000000 WA 0 0 8
从readelf的结果可以看到, 相比于目标文件, 可执行文件的st_value的值已经变得大得多了, 尽管仍然通过Ndx指向数据段和代码段, 但此时该字段的含义已经变成了对应符号在运行时的虚拟地址的空间了。我们使用gdb进行验证
$ gdb ./symbols
GNU gdb (GDB) 15.2
(gdb) info address another_function
Symbol "another_function" is at 0x1180 in a file compiled without debugging.
(gdb) info address global_var
Symbol "global_var" is at 0x4020 in a file compiled without debugging.
(gdb) info address static_global
Symbol "static_global" is at 0x4024 in a file compiled without debugging.
gdb的输出与符号表的输出统一
补:
在可重定位文件中(.o 文件,ET_REL)
此时文件尚未链接,并没有绝对的内存虚拟地址。
- 含义:节区内的偏移量(Section Offset)。
- 说明:只要符号已被定义,
st_value就表示该符号所在节区(由st_shndx指定)起始位置到该符号的字节偏移。 - 无论它是表示代码的函数,还是表示数据的变量,一律都是相对自己所在段的偏移
在可执行文件或共享库中(可运行程序或.so文件,ET_EXEC/ET_DYN)
此时文件已经过了链接器的处理,各个段被分配了固定的运行时加载地址。 - 含义:运行时的虚拟内存地址(Virtual Memory Address, VMA)。
- 说明:链接器在合并各个
.o文件后,会计算出符号在内存中的最终虚拟地址,并将其直接填入st_value。操作系统加载程序时,可以直接使用这个虚拟地址进行工作,无需再做复杂的偏移计算。 - 注:对于动态共享库(PIE /
.so),该值通常是相对于共享库加载基址的相对虚拟地址(RVA)。
两种特殊情况下的st_value
如果符号的节区索引 (st_shndx) 是几个特定的魔法值,st_value会有完全不同的解释: - 属于
SHN_COMMON(通常为未初始化的全局变量):- 此时
st_value不代表地址或偏移,而是代表该符号在最终被分配内存时需要的字节对齐约束(Alignment Requirement)。比如st_value = 4,意味着链接器未来给它分配内存时,地址必须是4的倍数。
- 此时
- 属于
SHN_UNDEF(未定义符号,如调用外部库的printf):- 此时符号的实体不在此文件中,
st_value通常恒为 0。
公式
如果 是可重定位文件 (.o):
- 此时符号的实体不在此文件中,
- 符号文件偏移 =
对应节区的文件基地址 (sh_offset) + st_value
如果是可执行文件 / 共享库: - 符号文件偏移 =
st_value - 对应段的虚拟基地址 (sh_addr) + 对应段的文件基地址 (sh_offset)
st_info
st_info中包含符号类型和绑定信息, 这里给出了控制它的值的方式具体信息如下
#define ELF32_ST_TYPE(i) ((i)&0xf) # 低 4 位
#define ELF32_ST_INFO(b, t) (((b)<<4) + ((t)&0xf)) # 高 4 位
符号类型如下:
| 名称 | 取值 | 说明 |
|---|---|---|
| STT_NOTYPE | 0 | 符号的类型没有定义. |
| STT_OBJECT | 1 | 符号与某个数据对象相关, 比如一个变量、数组等等. |
| STT_FUNC | 2 | 符号与某个函数或者其他可执行代码相关. |
| STT_SECTION | 3 | 符号与某个节区相关. 这种类型的符号表项主要用于重定位, 通常具有 STB_LOCAL 绑定. |
| STT_FILE | 4 | 一般情况下, 符号的名称给出了生成该目标文件相关的源文件的名称. 如果存在的话, 该符号具有 STB_LOCAL 绑定, 其节区索引是 SHN_ABS 且优先级比其他STB_LOCAL符号高. |
| STT_LOPROC~STT_HIPROC | 13~15 | 保留用于特定处理器 |
共享目标文件中的函数符号比较特殊,当另一个目标文件从共享文件中引用一个函数时,链接器自动为被引用符号创建过程链接表(plt)项,共享目标中出了STT_FUNC,其他符号将不会通过过程链接表自动被引用
补:
动态库符号引用与PlT机制
在ELF的动态链接(如调用.so共享库)中,链接器对函数符号和数据符号的引用有一套特殊的区别对待机制。
当前程序引用了外部共享库(.so)中的符号时:
- 函数符号 (STT_FUNC) :链接器会为它自动生成过程链接表(PLT, Procedure Linkage Table)项。
- 数据对象/变量 (STT_OBJECT) :不会生成PLT。变量通常直接通过全局偏移表(GOT, Global Offset Table)进行寻址访问。
PLT
PLT实际上是一段充当中间跳板的存根代码(Stub)。
当你调用外部共享库的函数(比如 printf)时,程序不是直接跳到printf的真实地址,而是:
- 先跳到该函数专属的PLT表项(如printf@plt)。
- PLT表项去查GOT表(记录真实地址的表格)。
- 最后再跳转到外部共享库中真正的函数地址。
优点
这种调用方->PLT->GOT->真实函数的额外间接层设计,带来了三大动态链接核心优势:
- 延迟绑定 (Lazy Binding) :
- 程序刚启动时,没必要把库里成百上千个函数的真实地址全找出来。
- 有了PLT跳板,函数地址只有在它第一次被真正调用时才会去解析,极大加快了程序的启动速度。
- 位置无关与代码共享 (PIC) :
- 共享库(.so)加载到内存的位置是随机的。有了PLT/GOT机制,主程序的代码不用被修改,只要更新表里的地址就行,从而实现了多进程完美共享同一份物理内存中的.so代码。
- 区分数据与函数:
- 变量(数据)只是被读取或写入,不需要执行,直接查 GOT 表即可。
- 函数需要执行流程跳转,不仅需要查地址,还需要“延迟解析”相关的机制,所以多加了一层PLT跳板
调外部变量直接查表(GOT),调外部函数要过多一层PLT。PLT的存在就是为了实现按需解析(延迟绑定)和动态跳转(不断定总结大概说的)
ELF文件的两种视图
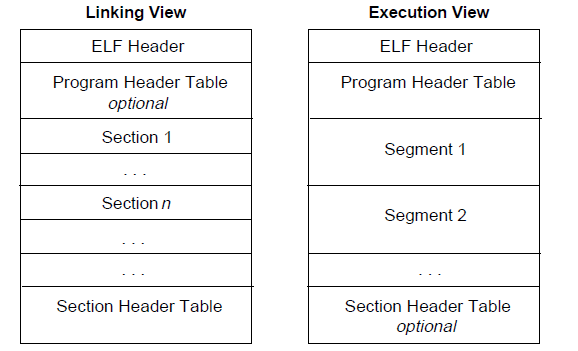
链接视图(linking view)
主要用于链接器处理,对应节头表,将文件按功能划分为多个节,主要用于静态链接过程,特点是粒度细(就是分类细),便于编译器生成和链接器处理,实际执行中,链接器会将多个节合并成段提高空间利用率
执行视图(execution view)
主要用于加载器处理,对应程序头表,描述了怎么将文件内容映射到进程的虚拟地址空间,关注段
按照权限合并,比如text和rodata都只读,data和bss都可读可写
常见段类型
- PT_LOAD,通常一个程序至少两个ptload段,一个只读,一个读写
- PT_DYNAMIC,动态链接段,对应节.dynamic,描述需要哪个so库(DT_NEEDED),符号表,重定位表,初始化函数,调用外部库函数
- PT_INTERP,解释器路径,对应节.interp,通常是字符串,路径指向动态链接器,运行前准备
- PT_NOTE,对应节.note.ABU-tag等,辅助说明
- PT_TLS,线程局部存储,对应节,.tdata,.tbss,告诉系统如何为每个线程初始化变量
- PT_GNU_STACK,栈控制,虚拟段,告诉栈是否可执行
PT,给操作系统内核看,决定段属性,DT,给动态链接器看,决定动态链接细节
补
哈希表节区
哈希表节区是用于存储哈希值的特殊节区,这些节区主要用于以下目的
- 完整性验证:存储文件或特定节区哈希值,用于验证文件是否被篡改
- 数字签名:支持代码签名机制,以验证软件的来源和完整性
- 安全启动:在嵌入式系统和安全启动过程中验证可执行文件
- 符号查找加速:某些哈希表用于加速符号查找过程
.hash是传统的哈希表节区, 使用GNU工具链则会以.gnu.hash替代, 其比传统的.hash更加高效, 占用的内存空间更小, 哈希函数也更加现代
静态链接
静态链接过程
在编译时将库代码直接复制到最终可执行文件的链接方式,过程如
- 编译器生成目标文件.o
- 链接器扫描所有目标文件和静态库.a
- 解析所有符号引用
- 将使用的库代码复制到可执行文件
- 生成完全独立的可执行文件
特点:地址预确定,链接阶段为所有符号分配最终虚拟地址
静态加载过程
- 解析elf文件头部,验证文件格式
- 根据程序头表将各段映射到链接时确定的固定虚拟地址
- 建立内存管理结构(mm_struct)管理虚拟内存区域(VMA)
- 初始化页表映射
- cpu直接从elf头部的e_entry获取入口地址开始执行
所有内存访问都使用绝对地址,通过MMU硬件将链接时确定的虚拟地址转换为物理地址。整个过程完全复用链接阶段确定的地址布局,无需运行时重定位。
特点:程序自包含,但可执行文件体积大
动态链接
动态链接过程
程序运行时才加载链接和链接所需库
- 编译器生成.o
- 链接器记录动态库.so以来信息
- 生成包含为解析符号的可执行文件
- 程序运行时,动态链接器(ld.so)
- 查找并加载所需共享库
- 解析符号引用
- 执行重定位操作
特点:地址延迟确定,实际地址在运行时才解析
动态加载过程
- 内核映射主程序的段到内存
- 加载动态链接器(ld.so)
- 动态链接器按需加载依赖的共享库
- 通过GOT和PLT机制完成符号解析和地址重定位
- 所有库代码采用位置无关代码(PLC)技术,支持多进程共享
- 支持ASLR(地址空间布局随机化)
特点:节省内存,依赖管理复杂
程序的初始化与终止机制 (.init & .fini)
初始化流 (.init / .init_array):
- 在主程序
main函数运行前,系统需要执行相关的初始化代码。 - 对于依赖的共享目标文件(
.so),动态链接器会根据DT_NEEDED记录的依赖图递归地执行初始化。顺序原则是:先初始化被依赖的库,最后初始化自身。
终止流 (.fini/.fini_array): - 当程序正常退出时,通过 atexit机制执行终止代码。
- 终止代码的执行顺序与初始化阶段完全相反。
- 注意:如果程序调用
_exit函数强制退出,或者因为接收到异常信号被杀掉,.fini终止代码将不会被保证执行。
动态链接相关核心节区.interp 节 (解释器)
- 对应
PT_INTERP程序头段,里面存储的是程序解释器(通常是动态链接器,如ld-linux.so)的绝对路径。 - 当系统执行程序时,并不会直接去跑该程序,而是先提取此路径加载解释器,把控制权交给解释器。由解释器负责映射目标文件、加载相关的动态库,最后再把控制权交还给应用程序。
- 地址冲突处理:由于可执行文件常被加载到固定地址,解释器通常被编译为“位置无关(地址独立)”,以避免两者的虚拟基址发生冲突。
.dynamic节 (动态链接键值表) - 对应
PT_DYNAMIC段,这是动态链接器工作时的“查表字典”。它本质上是一个由Elf32_Dyn结构体组成的键值对数组。 - 结构体中包含
d_tag(用于说明该项是什么信息)以及联合体d_un(存有具体的数值d_val或虚拟内存地址d_ptr)。
常见且核心的 Tag (d_tag) 包括: DT_NEEDED:声明当前文件依赖了哪个动态库(存的是字符串表偏移)。DT_STRTAB/DT_SYMTAB/DT_HASH:指出动态字符串表、动态符号表及符号哈希表在内存中的地址。DT_REL/DT_RELA:指向重定位表的地址,动态链接器依此进行地址修正。DT_INIT/DT_FINI:指明上述提到的初始化和终止函数的具体地址。DT_PLTGOT/DT_JMPREL:提供给延迟绑定机制(PLT/GOT)使用的相关表地址。DT_BIND_NOW:若出现此标记,动态链接器将无视延迟绑定,在移交控制权前强行完成所有符号的重定位。
| 名称 | 数值 | d_un | 可执行 | 共享 目标 | 说明 |
|---|---|---|---|---|---|
| DT_NULL | 0 | 忽略 | 必需 | 必需 | 标志着 _DYNAMIC 数组的末端。 |
| DT_NEEDED | 1 | d_val | 可选 | 可选 | 包含以NULL 结尾的字符串的字符串表偏移,该字符串给出某个需要的库的名称。所使用的索引为DT_STRTAB的下标。动态数组中可以包含很多个这种类型的标记。这些项在这种类型标记中的相对顺序比较重要。但是与其它的标记之前的顺序倒无所谓。对应的段为.gnu.version_r。 |
| DT_PLTRELSZ | 2 | d_val | 可选 | 可选 | 给出与过程链接表相关的重定位项的总的大小。如果存在DT_JMPREL类型的项,那么DT_PLTRELSZ也必须存在。 |
| DT_PLTGOT | 3 | d_ptr | 可选 | 可选 | 给出与过程链接表或者全局偏移表相关联的地址,对应的段.got.plt |
| DT_HASH | 4 | d_ptr | 必需 | 必需 | 此类型表项包含符号哈希表的地址。此哈希表指的是被 DT_SYMTAB 引用的符号表。 |
| DT_STRTAB | 5 | d_ptr | 必需 | 必需 | 此类型表项包含动态字符串表的地址。符号名、库名、和其它字符串都包含在此表中。对应的节的名字应该是.dynstr。 |
| DT_SYMTAB | 6 | d_ptr | 必需 | 必需 | 此类型表项包含动态符号表的地址。对 32 位的文件而言,这个符号表中的条目的类型为 Elf32_Sym。 |
| DT_RELA | 7 | d_ptr | 必需 | 可选 | 此类型表项包含重定位表的地址。此表中的元素包含显式的补齐,例如 32 位文件中的 Elf32_Rela。目标文件可能有多个重定位节区。在为可执行文件或者共享目标文件创建重定位表时,链接编辑器将这些节区连接起来,形成一个表。尽管在目标文件中这些节区相互独立,但是动态链接器把它们视为一个表。在动态链接器为可执行文件创建进程映像或者向一个进程映像中添加某个共享目标时,要读取重定位表并执行相关的动作。如果此元素存在,动态结构体中也必须包含 DT_RELASZ 和 DT_RELAENT 元素。如果对于某个文件来说,重定位是必需的话,那么 DT_RELA 或者 DT_REL 都可能存在。 |
| DT_RELASZ | 8 | d_val | 必需 | 可选 | 此类型表项包含 DT_RELA 重定位表的总字节大小。 |
| DT_RELAENT | 9 | d_val | 必需 | 可选 | 此类型表项包含 DT_RELA 重定位项的字节大小。 |
| DT_STRSZ | 10 | d_val | 必需 | 必需 | 此类型表项给出字符串表的字节大小,按字节数计算。 |
| DT_SYMENT | 11 | d_val | 必需 | 必需 | 此类型表项给出符号表项的字节大小。 |
| DT_INIT | 12 | d_ptr | 可选 | 可选 | 此类型表项给出初始化函数的地址。 |
| DT_FINI | 13 | d_ptr | 可选 | 可选 | 此类型表项给出结束函数(Termination Function)的地址。 |
| DT_SONAME | 14 | d_val | 忽略 | 可选 | 此类型表项给出一个以 NULL 结尾的字符串的字符串表偏移,对应的字符串是某个共享目标的名称。该偏移实际上是 DT_STRTAB 中的索引。 |
| DT_RPATH | 15 | d_val | 可选 | 忽略 | 此类型表项包含以 NULL 结尾的字符串的字符串表偏移,对应的字符串是搜索库时使用的搜索路径。该偏移实际上是 DT_STRTAB 中的索引。 |
| DT_SYMBOLIC | 16 | 忽略 | 忽略 | 可选 | 如果这种类型表项出现在共享目标库中,那么这将会改变动态链接器的符号解析算法。动态连接器将首先选择从共享目标文件本身开始搜索符号,只有在搜索失败时,才会选择从可执行文件中搜索相应的符号。 |
| DT_REL | 17 | d_ptr | 必需 | 可选 | 此类型表项与 DT_RELA类型的表项类似,只是其表格中包含隐式的补齐,对 32 位文件而言,就是 Elf32_Rel。如果ELF文件中包含此元素,那么动态结构中也必须包含 DT_RELSZ 和 DT_RELENT 类型的元素。 |
| DT_RELSZ | 18 | d_val | 必需 | 可选 | 此类型表项包含 DT_REL 重定位表的总字节大小。 |
| DT_RELENT | 19 | d_val | 必需 | 可选 | 此类型表项包含 DT_REL 重定位项的字节大小。 |
| DT_PLTREL | 20 | d_val | 可选 | 可选 | 此类型表项给出过程链接表所引用的重定位项的地址。根据具体情况, d_val 对应的地址可能包含 DT_REL 或者 DT_RELA。过程链接表中的所有重定位都必须采用相同的重定位方式。 |
| DT_DEBUG | 21 | d_ptr | 可选 | 忽略 | 此类型表项用于调试。ABI 未规定其内容,访问这些条目的程序可能与 ABI 不兼容。 |
| DT_TEXTREL | 22 | 忽略 | 可选 | 可选 | 如果文件中不包含此类型的表项,则表示没有任何重定位表项能够造成对不可写段的修改。如果存在的话,则可能存在若干重定位项请求对不可写段进行修改,因此,动态链接器可以做相应的准备。 |
| DT_JMPREL | 23 | d_ptr | 可选 | 可选 | 该类型的条目的 d_ptr 成员包含了过程链接表的地址,并且索引时应该会把该地址强制转换为对应的重定位表项类型的指针。把重定位表项分开有利于让动态链接器在进程初始化时忽略它们(开启了延迟绑定)。如果存在此成员,相关的 DT_PLTRELSZ 和 DT_PLTREL 必须也存在。 |
| DT_BIND_NOW | 24 | 忽略 | 可选 | 可选 | 如果可执行文件或者共享目标文件中存在此类型的表项的话,动态链接器在将控制权转交给程序前,应该将该文件的所有需要重定位的地址都进行重定位。这个表项的优先权高于延迟绑定,可以通过环境变量或者dlopen(BA_LIB)来设置。 |
| DT_LOPROC ~DT_HIPROC | 0x70000000 ~0x7fffffff | 未指定 | 未指定 | 未指定 | 这个范围的表项是保留给处理器特定的语义的。 |
.dynstr
.dynsym
动态链接的ELF文件具有专门的动态符号表,其使用的结构就是Elf32_Sym,但是其存储的节为.dynsym。这里再次给出Elf32_Sym的结构
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility under glibc>=2.2 */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
需要注意的是 .dynsym 是运行时所需的,ELF 文件中 export/import 的符号信息全在这里。但是,.symtab 节中存储的信息是编译时的符号信息,它们在 strip 之后会被删除掉。
我们主要关注动态符号中的两个成员
- st_name, 该成员保存着动态符号在.dynstr 表(动态字符串表)中的偏移。
- st_value,如果这个符号被导出,这个符号保存着对应的虚拟地址。
符号版本
动态符号与指向它的Elf_Verdef保存在.gnu.version段中,其中,由Elf_Verneed结构体构成的数组的每个元素对应动态符号表的一项。其实,这个结构体就只有一个域:那就是一个16位的整数,表示gnu.verion_r段中的下标。
在这样的情况下,动态链接器使用Elf_Rel结构体成员r_info中的下标同时作为.dynsym段和gnu.version段的下标。这样就可以一一对应到每一个符号到底是那个版本的了。
Relocation Related Sections
链接器在处理目标文件时,需要对目标文件中的某些位置进行重定位,即将符号指向恰当的位置,确保程序正常执行。例如,当程序调用了一个函数时,相关的调用指令必须把控制流交给适当的目标执行地址。
在ELF文件中,对于每一个需要重定位的ELF节都有对应的重定位表,比如说.text节如果需要重定位,那么其对应的重定位表为.rel.text。
举个例子,当一个程序导入某个函数时,.dynstr就会包含对应函数名称的字符串,.dynsym中就会包含一个具有相应名称的动态字符串表的符号(Elf_Sym),在rel.dyn中就会包含一个指向这个符号的的重定位表项
.rel(a).dyn/.rel(a).plt
.rel.dyn包含了动态链接的二进制文件中需要重定位的变量的信息,这些信息在加载的时候必须完全确定。而.rel.plt包含了需要重定位的函数的信息。这两类重定位节都使用如下的结构
typedef struct {
Elf32_Addr r_offset;
Elf32_Word r_info;
} Elf32_Rel;
typedef struct {
Elf32_Addr r_offset;
Elf32_Word r_info;
Elf32_Sword r_addend;
} Elf32_Rela;
Elf32_Rela类型的表项包含明确的补齐信息。 Elf32_Rel类型的表项在将被修改的位置保存隐式的补齐信息。由于处理器体系结构的原因,这两种形式都存在,甚至是必需的。因此,对特定机器的实现可以仅使用一种形式,也可以根据上下文使用两种形式。
一般来说,32位程序只使用Elf32_Rel,64位程序只使用Elf32_Rela。
其中,每个字段的说明如下
| 成员 | 说明 |
|---|---|
| r_offset | 此成员给出了需要重定位的位置。对于一个可重定位文件而言,此值是从需要重定位的符号所在节区头部开始到将被重定位的位置之间的字节偏移。对于可执行文件或者共享目标文件而言,其取值是需要重定位的虚拟地址,一般而言,也就是说我们所说的 GOT 表的地址。 |
| r_info | 此成员给出需要重定位的符号的符号表索引,以及相应的重定位类型。 例如一个调用指令的重定位项将包含被调用函数的符号表索引。如果索引是 STN_UNDEF,那么重定位使用 0 作为“符号值”。此外,重定位类型是和处理器相关的。 |
| r_addend | 此成员给出一个常量补齐,用来计算将被填充到可重定位字段的数值。 |
当程序代码引用一个重定位项的重定位类型或者符号表索引时,这个索引是对表项的r_info成员应用ELF32_R_TYPE或者ELF32_R_SYM的结果。 也就是说r_info的高三个字节对应的值表示这个动态符号在.dynsym符号表中的位置。
#define ELF32_R_SYM(i) ((i)>>8)
#define ELF32_R_TYPE(i) ((unsigned char)(i))
#define ELF32_R_INFO(s,t) (((s)<<8)+(unsigned char)(t))
重定位节区会引用两个其它节区:符号表、要修改的节区。节区头部的sh_info和sh_link成员给出相应的关系。
重定位类型
重定位表项描述了如何修改相关的指令与数据域,其对应的比特位如下
其中,word32指定了一个32比特的变量,占用4个字节,对齐方式任意。这些值使用和Intel架构中其它字类似的字节序,一般都是小端序
重定位计算与类型解析
在将一个或多个可重定位文件(.o)合并、转换为可执行文件或共享目标文件时,链接器会首先决定如何布局各个被输入的段,接着更新符号表,最后实施重定位操作。可执行文件与共享目标文件的重定位方法基本相同。
在这部分重定位的计算规则中,通常使用以下专用记号代表特定的运行时或链接时数据:
- A (Addend):重定位计算中使用的对齐/补齐常数值。
- B (Base):共享目标文件在运行阶段实际被加载到内存里的基地址(通常编译时假定为0,运行时会发生改变)。
- G (Global):执行时,该重定位符号在全局偏移表(GOT)中的具体偏移量。
- GOT (Global Offset Table):全局偏移表在内存中的首地址。
- L (Linkage):过程链接表(PLT)里某个函数的入口偏移或虚拟地址。链接器事先构造好初始的过程链接表,由动态链接器在运行期间负责修改。
- P (Place):需要被重定位修改的存储单元自身的内存位置(等于 r_offset 的值,可以是段内偏移或绝对虚拟地址)。
- S (Symbol):重定位表项中 r_info 索引所指向的那个符号的实际真值(如变量绝对地址或相对偏移)。
底层处理机制要求:
重定位项的 r_offset 字段指明了受影响的存储单元的起始偏移或虚拟地址。
在Intel 32位架构下,程序一般仅采用具有隐式补齐的 ELF32_REL 表项结构,链接器会直接将待修改内存区域原本保留的数据作为补齐值(A)参与运算,且全部计算过程保持与处理器一致的小端字节序。
常见重定位类型及其计算规则定义:
R_386_32
- 计算方式:S + A
- 含义:直接将符号地址与常数相加,得出最终绝对地址填入目标。
R_386_PC32 - 计算方式:S + A – P
- 含义:计算相对于当前指令所处位置(Place)的相对偏移,常用于近跳转指令或相对寻址。
R_386_GOT32 - 计算方式:G + A – P
- 含义:计算出从全局偏移表基址到该符号对应GOT表项之间的距离,遇到此重定位类型会让链接器强制创建一个GOT表。
R_386_PLT32 - 计算方式:L + A – P
- 含义:计算跳转到目标符号的PLT表项的相对地址。同样会触发链接器强制建立过程链接表。
R_386_COPY - 计算方式:无
- 含义:专为动态链接而生。它的偏移项指向可写数据段,通知动态链接器把对应共享对象里面属于该符号的数据直接复制到当前指定的内存空间中。
R_386_GLOB_DAT - 计算方式:S
- 含义:强行将GOT表当中的某个特殊槽位设置为目标符号的绝对真实地址。
R_386_JMP_SLOT - 计算方式:S
- 含义:专为动态函数的PLT解析准备。动态链接器解析完毕后,直接把目的函数 S 的绝对地址覆盖进这个偏移所指向的表项中,从而实现后续控制权的快速转移。
R_386_RELATIVE - 计算方式:B + A
- 含义:基于共享目标文件的虚拟基地址进行平移(B+A),把所在地址的真实虚拟地址计算出来并填入。此类重定位项的符号表索引一般置0(不依赖特定符号解析,仅重定位地址)。
R_386_GOTOFF - 计算方式:S + A – GOT
- 含义:求出某符号的实际值与GOT基地址之间的偏差量,此操作同样强制要求链接器布置GOT表。
R_386_GOTPC - 计算方式:S + A – P
- 含义:类似于PC32相对寻址计算,专门用于定位GOT表自身的位置(引用的特殊符号为 GLOBAL_OFFSET_TABLE),用来引导程序找到自己的全局偏移表的基址。
Global Offset Table
GOT表在ELF文件中分为两个部分
- .got,存储全局变量的引用。
- .got.plt,存储函数的引用。
其相应的值由能够解析.rel.plt段中的重定位的动态链接器来填写。
通常来说,地址独立代码不能包含绝对虚拟地址。GOT表中包含了隐藏的绝对地址,这使得在不违背位置无关性以及程序代码段兼容的情况下,得到相关符号的绝对地址。一个程序可以使用位置独立代码来引用它的GOT表,然后提取出来绝对的数值,以便于将位置独立的引用重定向到绝对的地址。 这个表对于 System V环境中的动态链接来说是必要的,但其具体的内容以及形式依赖于处理器。
初始时,got表中包含重定向入口所需要的信息。当一个系统为可加载的目标文件创建内存段时,动态链接器会处理重定位项,其中的一些项的类型可能是R_386_GLOB_DAT,这会指向got 表。动态链接器会决定相关的符号的值,计算它们的绝对地址,然后将合适的内存表项设置为相应的值。尽管在链接器建立目标文件时,绝对地址还处于未知状态,动态链接器知道所有内存段的地址,因为可以计算所包含的符号的绝对地址。
如果一个程序需要直接访问一个符号的绝对地址,那么这个符号将会有一个got表项。由于可执行文件以及共享目标文件都有单独的表项,所以一个符号的地址可能会出现在多个表中。动态链接器在把权限给到进程镜像中的代码段前,会处理所有的got表中的重定位项,以便于确定所有的绝对地址在执行过程中是可以访问的。
GOT表中的第0项包含动态结构的地址,用符号 _DYNAMIC来进行引用。这使得一个程序,例如动态链接器,在没有执行其重定向前可以找到对应的动态结构。这对于动态链接器来说是非常重要的,因为它必须在不依赖其它程序的情况下可以重定位自己的内存镜像。
在不同的程序中,系统可能会为同一共享目标文件选择不同的内存段地址;甚至对于同一个程序,在不同的执行过程中,也会有不同的库地址。然而,一旦进程镜像被建立,内存段的地址就不会再改变,只要一个进程还存在,它的内存段地址将处于固定的位置。
GOT表的形式以及解释依赖于具体的处理器,对于Intel架构来说,_GLOBAL_OFFSET_TABLE_ 符号可能被用来访问这个表。
extern Elf32_Addr _GLOBAL_OFFSET_TABLE[];
_GLOBAL_OFFSET_TABLE_可能会在.got节的中间,以便于可以使用正负索引来访问这个表。
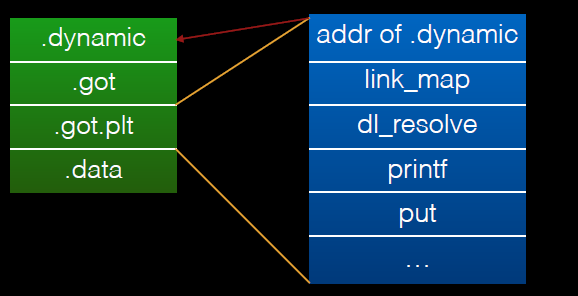
在 Linux 的实现中,.got.plt 的前三项的具体的含义如下
- GOT[0],.dynamic的地址。
- GOT[1],指向内部类型为link_map的指针,只会在动态装载器中使用,包含了进行符号解析需要的当前ELF对象的信息。每个link_map都是一条双向链表的一个节点,而这个链表保存了所有加载的ELF对象的信息。
- GOT[2],指向动态装载器中
_dl_runtime_resolve函数的指针。
.got.plt后面的项则是程序中不同.so中函数的引用地址。下面给出一个相应的关系。
Procedure Linkage Table
GOT表用来将位置独立的地址重定向为绝对地址,与此类似,PLT表将位置独立的函数重定向到绝对地址。主要包括两部分
- .plt,与常见导入的函数有关,如 read 等函数。
- .plt.got,与动态链接有关系。
在动态链接下,程序模块之间包含了大量的函数引用,程序开始执行前,动态链接会耗费不少时间用于解决模块之间的函数引用的符号查找以及重定位。但是,在一个程序运行过程中,可能很多函数在程序执行完时都不会用到,因此一开始就把所有函数都链接好是一种浪费,所以 ELF 采用了一种延迟绑定的做法,其基本思想是函数第一次被用到时才进行绑定(符号查找,重定位等),如果没有用则不进行绑定。所以程序开始执行前,模块间的函数调用都没有进行绑定,而是需要用到时才由动态链接器负责绑定。
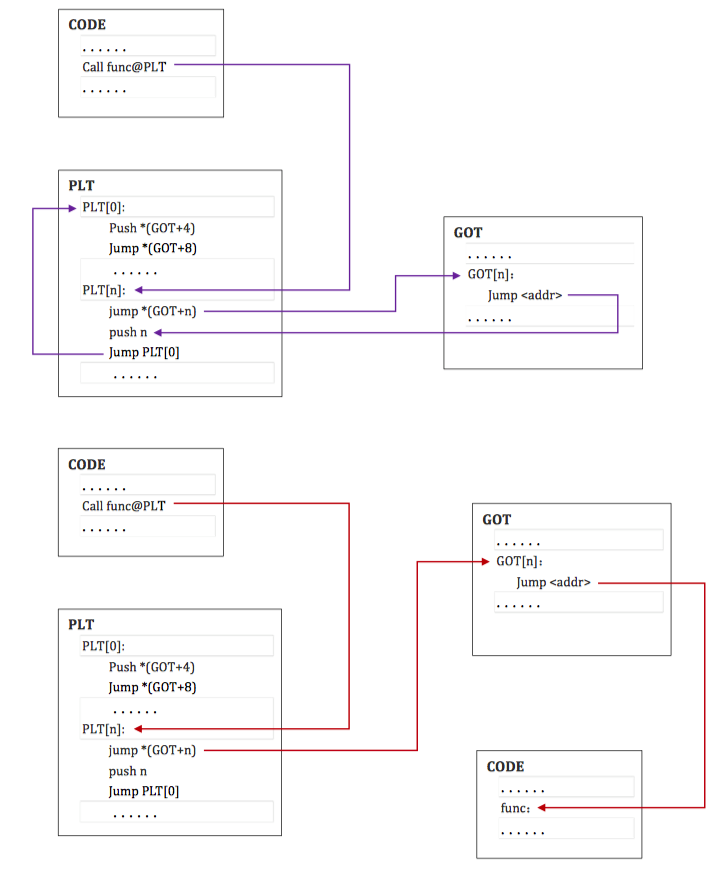
链接编辑器不能够解析执行流转换(比如程序调用),即从一个可执行文件或者共享目标文件到另一个文件。链接器安排程序将控制权交给过程链接表中的表项。在 Intel 架构中,过程链接表存在于共享代码段中,但是他们会使用在 GOT 表中的数据。动态链接器会决定目标的绝对地址,并且会修改相应的 GOT 表中的内存镜像。因此,动态链接器可以在不违背位置独立以及程序代码段兼容的情况下,重定向 PLT 项。可执行文件和共享目标文件都有独立的 PLT 表。
绝对地址的过程链接表如下
.PLT0:pushl got_plus_4
jmp *got_plus_8
nop; nop
nop; nop
.PLT1:jmp *name1_in_GOT
pushl $offset@PC
jmp .PLT0@PC
.PLT2:jmp *name2_in_GOT
push $offset
jmp .PLT0@PC
...
位置无关的过程链接表的地址如下
.PLT0:pushl 4(%ebx)
jmp *8(%ebx)
nop; nop
nop; nop
.PLT1:jmp *name1_in_GOT(%ebx)
pushl $offset
jmp .PLT0@PC
.PLT2:jmp *name2_in_GOT(%ebx)
push $offset
jmp .PLT0@PC
...
可以看出过程链接表针对于绝对地址以及位置独立的代码的处理不同。但是动态链接器处理它们时,所使用的接口是一样的。
动态链接器和程序按照如下方式解析过程链接表和全局偏移表的符号引用。
- 当第一次建立程序的内存镜像时,动态链接器将全局偏移表的第二个和第三个项设置为特殊的值,下面的步骤会仔细解释这些数值。
- 如果过程链接表是位置独立的话,那么 GOT 表的地址必须在 ebx 寄存器中。每一个进程镜像中的共享目标文件都有独立的 PLT 表,并且程序只在同一个目标文件将控制流交给 PLT 表项。因此,调用函数负责在调用 PLT表项之前,将全局偏移表的基地址设置为寄存器中。
- 这里举个例子,假设程序调用了name1,它将控制权交给了 lable .PLT1。
- 那么,第一条指令将会跳转到全局偏移表中 name1的地址。初始时,全局偏移表中包含 PLT 中下一条 pushl指令的地址,并不是 name1的实际地址。
- 因此,程序将一个重定向偏移(reloc_index)压到栈上。重定位偏移是 32 位的,并且是非负的数值。此外,重定位表项的类型为 R_386_JMP_SLOT,并且它将会说明在之前 jmp 指令中使用的全局偏移表项在 GOT 表中的偏移。重定位表项也包含了一个符号表索引,因此告诉动态链接器什么符号目前正在被引用。在这个例子中,就是 name1了。
- 在压入重定位偏移后,程序会跳转到 .PLT0,这是过程链接表的第一个表项。pushl 指令将 GOT 表的第二个表项(got_plus_4 或者4(%ebx),当前ELF对象的信息)压到栈上,然后给动态链接器一个识别信息。此后,程序会跳转到第三个全局偏移表项(got_plus_8 或者8(%ebx),指向动态装载器中_dl_runtime_resolve函数的指针) 处,这将会将程序流交给动态链接器。
- 当动态链接器接收到控制权后,他将会进行出栈操作,查看重定位表项,找到对应的符号的值,将 name1 的地址存储在全局偏移表项中,然后将控制权交给目的地址。
- 过程链接表执行之后,程序的控制权将会直接交给 name1 函数,而且此后再也不会调用动态链接器来解析这个函数。也就是说,在 .PLT1 处的 jmp 指令将会直接跳转到 name1 处,而不是再次执行 pushl 指令。
总体流程如下图所示,蓝线表示首次执行的流程图,红线表示第二次以后调用的流程图:
LD_BIND_NOW环境变量可以改变动态链接器的行为。如果它的值非空的话,动态链接器在将控制权交给程序之前会执行PLT表项。也就是说,动态链接器在进程初始化过程中执行类型为R_3862_JMP_SLOT的重定位表项。否则的话,动态链接表会对过程链接表项进行延迟绑定,直到第一次执行对应的表项时,才会今次那个符号解析以及重定位
惰性绑定
惰性绑定(延迟绑定)特点
- 核心优势:
- 提高启动性能并节省资源:在大型程序中,包含成百上千个外部函数调用,但实际运行中往往只会执行其中一小部分。如果程序启动时就把所有函数全部解析并绑定好,会极其耗时。惰性绑定(通过PLT/GOT机制)允许“用到哪个函数,才去解析哪个函数”,从而大大减轻了动态链接的初始负载,加快了程序的启动速度。
- 存在的隐患(不可预期性):
- 初次调用存在延迟(性能抖动):当某个函数被第一次调用时,系统必须挂起当前的业务逻辑,转而去执行复杂的符号查找和重定位操作(也就是执行
_dl_runtime_resolve)。这会导致第一次调用的耗时远高于后续调用,对于对实时性要求极高(不能忍受延迟抖动)的应用程序来说,这是不可接受的。 - 运行时崩溃风险:如果动态库版本不匹配或某个函数根本不存在,在惰性绑定下,程序启动时是无法发现的。只有当程序执行到那一行代码,试图去解析该符号时才会报错,导致动态链接器直接终止程序(Crash)。
- 解决方案:可以通过设置环境变量
LD_BIND_NOW(或类似机制)强制关闭惰性绑定。这样所有函数在程序获取控制权之前(初始化阶段)就会全部解析完毕,虽牺牲了启动速度,但保证了运行时的稳定性和耗时一致性。
_dl_runtime_resolve过程解释
当开启惰性绑定时,程序第一次调用外部函数会跳入 PLT 表,并最终调用动态装载器的核心函数:_dl_runtime_resolve(link_map_obj, reloc_index)
这里的两个参数:
link_map_obj:当前 ELF 库的状态信息(从 GOT[1] 获取)。reloc_index:当前调用函数对应的重定位索引(由 PLT 里的push指令压入栈中提供)。
在这个函数内部,系统(以 32 位为例)执行了以下查表验证步骤:
- 定位重定位表项:
Elf32_Rel *reloc = JMPREL + index
通过基地址JMPREL(跳板重定位表起址)加上偏移量,找到当前函数对应的那个重定位表项(记录了需要修改哪里,以及符号信息在哪里)。 - 定位具体的符号(函数)实体:
Elf32_Sym *sym = &SYMTAB[((reloc->r_info)>>8)]
从重定位表项的r_info字段高 24 位中提取出符号的索引号,然后去.dynsym(动态符号表,即SYMTAB)中查找到该函数的详细描述结构体Elf32_Sym。 - 安全校验(验证重定位类型):
assert (((reloc->r_info)&0xff) == 0x7 )
检查r_info的最低字节,确保它的重定位类型确实是R_386_JMP_SLOT(值为 7),因为只有这个类型才用于处理 PLT 的函数延迟绑定机制。 - 检查符号可见性与解析状态:
通过判断符号的st_other属性,检查这个符号是不是隐藏的,以及是否在之前的流程中已经被解析过了。如果已经解析过,就直接跳过耗时的查找步骤。 - 处理符号多版本(Version 机制):
uint16_t ndx = VERSYM[ (reloc->r_info) >> 8]
在现代 Linux 中,同一个动态库可能存在同名函数的多个版本。系统通过查找VERSYM数组,得到该符号对应的版本号索引,以确保后面绑定的是正确版本的函数实现。 - 提取字符串名称,准备最终的物理寻址:
name = STRTAB + sym->st_name
最后,通过符号结构体中的st_name偏移量,去动态字符串表(.dynstr/STRTAB)中提取出真正的函数名字(比如字符串"printf")。
拿到名字和版本号后,动态链接器就会去加载的共享库(.so)的内存空间中进行实际的哈希查找,找到真正的函数内存物理/虚拟地址,并将其回填到程序的 GOT 表中,完成绑定。后续的调用就不再需要经历这个繁琐的过程了。
异常处理与栈回溯机制 (.eh_frame 相关)
.eh_frame
- 该节区主要存放与栈回溯(Stack Unwinding)相关的调用帧信息(Call Frame Information, CFI)。
- 它的核心作用是支持高级语言(典型的如 C++)的异常处理机制(throw/catch)。当程序发生异常需要跳转时,运行时系统必须顺着调用链逐层向外“展开”调用栈,恢复每一层函数的寄存器状态和栈指针,去寻找能够处理该异常的 catch 块。这些指导系统如何安全“退栈”的数据就记录在这里。
- 即使程序没有异常处理,调试器(如 GDB)和性能诊断工具在追踪函数调用链(生成 Backtrace)时,也常常依赖此节区的数据进行精确定位。
- 在底层结构上,它由一系列的 CIE(公共信息表项,Common Information Entry)和 FDE(帧描述表项,Frame Description Entry)组成。其中 FDE 负责描述单个具体函数的栈帧解析规则,而 CIE 则存放多个 FDE 共享的基础规则以节省空间。
.eh_frame_hdr
- 可以将其理解为
.eh_frame的全局索引表或加速目录。 - 由于程序中包含极多的函数,
.eh_frame里会存放海量且长度不一的 FDE 数据。如果在发生异常时对整个节区进行线性遍历查找,性能损耗将非常大。 - 为了解决这个问题,链接器会生成
.eh_frame_hdr,里面包含一个根据程序计数器(PC,即代码运行地址)预先排好序的二进制搜索树/查找表。 - 当需要栈回溯时,运行时系统(如 libgcc 或 libunwind)可以直接在这个头部索引中通过二分查找,利用当前指令地址极速定位到
.eh_frame中对应的FDE结构,从而大幅提升异常展开的执行效率。
指令
readelf
基本语法readelf [options] elffile
- -h:显示elf header中的信息
- -S:列出文件的所有节,显示section headers的相关信息(name,type,address以及offset等)
- -l:列出文件的程序头表以及所有段
- -s:显示文件的符号表信息,包括函数名,全局变量等及其地址
- -r:显示重定位信息,涉及动态链接过程
- -d:显示动态段的内容,包括共享库依赖,符号表位置等
- -n:显示文件中的注释段内容
- -a:显示文件的所有信息
- -x :以16进制查看特定节的内容
更多信息通过man查看readelf
问:
dll加载次数,动态链接过程, pltgot细节过程
文章学习:
https://ciphersaw.me/ctf-wiki/executable/elf/elf_structure/#dynstr








