
MIPS架构是一种采取精简指令集(RISC)的处理器架构,它基于一种固定长度的定期编码指令集,并采用导入/存储(Load/Store)数据模型,经改进,这种架构可支持高级语言的优化执行。其算数和逻辑运算采用三个操作数的形式,允许编译器优化复杂表达式
补:我们的虚拟机基本都是ubuntu,也就是基于8086架构,所以这里我们学习mips需要理由qemu来模拟这个架构,而QEMU代表快速模拟器,是虚拟化领域的一个重要工具,能够在单个硬件平台上同时运行多个操作系统。以其能够仿真广泛的客户系统和架构而闻名,QEMU是创建和管理虚拟环境的多功能解决方案。它作为一个类型1虚拟机运行,直接与物理硬件接口,这与其他虚拟化技术有显著的不同。通过整合像Intel VT和AMD-V这样的硬件虚拟化技术,QEMU优化了虚拟机的性能,为开发人员和IT专业人员提供了一个强大的平台,用于模拟各种计算环境,无需为每个系统提供专用硬件
#!/bin/sh
# 安装QEMU及相关工具
sudo apt install qemu
sudo apt install qemu-system qemu-user-static binfmt-support
# 安装ARM架构编译器和依赖
sudo apt install libncurses5-dev gcc-arm-linux-gnueabi build-essential
# 安装MIPS架构编译器
sudo apt-get install gcc-mips-linux-gnu
sudo apt-get install gcc-mipsel-linux-gnu
sudo apt-get install gcc-mips64-linux-gnuabi64
sudo apt-get install gcc-mips64el-linux-gnuabi64
# 安装多架构gdb调试依赖
sudo apt install gdb-multiarch
mips指令集
mips指令集结构
MIPS指令集是精简指令集(RISC)架构的典型代表,所有指令长度为32位。指令分为三种类型:R型、I型和J型,每种类型有不同的操作码格式。
- R型指令(寄存器-寄存器操作):适用于寄存器之间的运算,通常包括算术和逻辑操作。
- I型指令(立即数操作):适用于需要立即数或地址的操作。
- J型指令(跳转操作):用于跳转指令。
指令分类
算术运算指令
- add:有符号整数加法,add rd,rs,rt
- addi:有符号整数加法(立即数),addi rt,rs,imm
- sub:有符号整数减法,sub rd,rs,imm
- mult:有符号乘法,mult rs,rt
- div:有符号除法,div rs,rt
逻辑运算指令
- and:按位与,and rd,rs,rt
- andi:按位与(立即数),andi rt,rs,imm
- or:按位或,or rd,rs,rt
- ori:按位或(立即数),ori rt,rs,imm
- xor:按位异或,xor rd,rs,rt
- nor:按位取反或,nor rd,rs,rt
移位指令
- sll:左移,sll rd,rt,shamt
- srl:逻辑右移,srl rd,rt,shamt
- sra:算术右移,sra rd,rt,shamt
数据传输指令
- lw:加载字,lw rt,offset(rs)
- sw:存储字,sw rt,offset(rs)
- lb:加载字节,lb rt,offset(rs)
- sb:存储字节,sb rt,offset(rs)
条件分支指令
- beq:等于则分支跳转,beq rs,rt,label
- bne:不等则分支跳转,bne rs,rt,label
- bgtz:大于零则跳转,bgtz rs,label
- blez:小于等于零则跳转,blez rs,label
跳转指令
- j:无条件跳转,j label
- jal:跳转并链接,jal label
- jr:寄存器跳转,js rs
补:
特殊指令 - syscall:用于系统调用,通常用于程序和操作系统之间的交互
- nop:空操作指令,执行无效果,通常用于指令延迟槽
碎指令补充喵: - addiu:add immediate unsigned,即为左侧操作数加上立即数,但与addi不同的是addiu不会检测最终结果是否溢出。举例:
addiu $sp,-0x68等价于$sp=$sp-0x68(伪c赋值语句) - sw:store word,将寄存器的值保存到某地址,举例:
sw $ra,0x60+var_s4($sp)等价于*($sp+0x60+var_s4)=$ra - move:用于寄存器之间值的传递,举例:
move $fp,$sp等价于$fp=$sp - li:load immediate,用于将立即数传送给寄存器,举例
li $gp,(_GLOBAL_OFFSET_TABLE_+0x7FF0)等价于$fp=(_GLOBAL_OFFSET_TABLE_+0x7FF0) - la:load address,用于将地址传送至寄存器中,多用于通过地址获取数据段中的地址
- lw:load word,从某地址加载一个word类型的值到寄存器中,举例
lw $fp,0x10($fp)等价于$gp=*($fp+0x10) - lui:load upper immediate,取立即数并放到寄存器高16位,剩下的低16位使用0填充
- lwc1:load word coprocessor 1,将浮点数加载到浮点寄存器
- swc1:store word coprocessor 1,将浮点寄存器的数据保存到相应的内存
- jalr:jump and link register,格式为jalr oprd1 oprd2或jalr oprd1,当格式为前者时在调用函数后会将返回地址存入到oprd2中,当格式为后者时返回地址将保存到
$ra寄存器 - nop:滑动指令
- lhu:load halfword unsigned,加载半个字(1字节)的数据到目标寄存器
- sh:store halfword,传送半个字到目标内存
cvt.d.s $f0, $f1:Convert Double to Single,浮点数转换指令,在某些编译器环境下,被用于将$f1中的浮点数转换为的特定格式(如整型)并存入$f0(两个浮点寄存器)addiu $v1, $fp, 0x168+buffer:普通的addiu只有两个参数(如$sp, -0x60)。当出现三个参数时,它的逻辑是:目标寄存器=源寄存器+立即数,这里表示$v1=$fp+0x168+buffer(buffer的地址)sdc1 $f0, 0x168+var_148($sp):Store DoubleWord from Coprocessor 1,该指令用于将浮点寄存器$f0里的64位双精度浮点数存入内存地址。在传感器数据处理时,经常会看到对浮点协处理器(coprocessor 1)的操作
常用寄存器
MIPS有32个通用寄存器,每个寄存器在约定上有特定用途
| 寄存器编号 | 名称 | 功能 |
|---|---|---|
| $0 | $zero | 常量寄存器(Constant Value 0),永远为0 |
| $1 | $at | 汇编暂存器(Assembly Temporary),用于处理在加载16位以上的大常数时使用,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里;可以显式地使用这个寄存器。 |
| $2 ~ $3 | $v0 ~ $v1 | 用于存储表达式或者函数返回的 值(value) |
| $4 ~ $7 | $a0 ~ $a3 | 存放函数调用时的 参数(Arguments) |
| $8 ~ $15 | $t0 ~ $t7 | 存放 临时变量(Temporary variable) |
| $16 ~ $23 | $s0 ~ $s7 | 保存(Saved)寄存器,在函数调用和返回时可能需要保存和恢复调用者寄存器的值。 |
| $24 ~ $25 | $t8 ~ $t9 | 同 t0 ~ t7 |
| $26 ~ $27 | $k0 ~ $k1 | 使用编译器编译出来的程序不会使用这两个寄存器,这两个用于保存异常处理和中断的返回值,为操作系统 保留(Keep)使用。 |
| $28 | $gp | 全局指针(Global Pointer) |
| $29 | $sp | 栈指针(Stack Pointer),指向栈顶 |
| $30 | $fp/$s8 | $30可以当作第9个Saved寄存器 $s8,也可以当作栈帧指针(Frame Pointer) $fp 使用,这得看编译器的类型。 |
| $31 | $ra | 保存函数的 返回地址(Return Address) |
MIPS架构最多支持4个协处理器(Co-Processor),该架构强制要求存在协处理器CP0,因为MMU,异常处理,Cache控制,断点控制等功能都依赖于CP0实现
$sr:全称Status Register(状态寄存器),它位于CP0的Reg12,该寄存器可以反应CPU的状态以及控制CPU,下图最显眼的是8个中断控制标志位IM(Interrupt Msak)和标志着处理器大小端的RE(Reverse Endianess)
| Register Number (寄存器号码) | Sel1 | Register Name (寄存器名称) | Function (功能) | Reference (参考资料) | Compliance Level (合规级别) |
|---|---|---|---|---|---|
| 12 | 0 | Status | Processor status and control | Section 9.20 on page 120 | Required |

$lo,$hi:这两个寄存器用来存放整数乘除法的结果,可以使用mthi和mtlo指令对$hi,$lo寄存器进行操作。在除法计算中,$lo存放运算之后的商,而$hi寄存器存放余数。两者均不是通用寄存器,除了乘除法之外不能作其他操作$pc:Program Counter(程序计数器),类似于x86的eip,标志着当前要执行的指令$f0~$f31:表示浮点寄存器(floating-point register)p/x $sr在gdb中可以拿来查看status register的值
补:- MIPS固定4字节指令长度
- 栈是从内存的高地址向低地址方面增长的
- 叶子函数:函数内部没有再调用其他函数
- 非叶子函数:函数内部调用其他函数
- 流水线效应:在分析MIPS汇编代码时会发现,其跳转到函数或者分支跳转指令导致的分支延迟效应,在分支跳转语句后面的那条语句叫做分支延迟槽,当跳转语句刚执行的一瞬间,跳转到的地址刚填充好(填充到程序计数器),还没有执行程序计数器中存放的指令,分支延迟槽的指令已经被执行了,这就是流水线效应(几条指令被同时执行,只是处于不同的阶段,mips不像其他架构那样存在流水线阻塞),为了避免出现问题,因此在分支跳转语句的下一条指令通常是nop指令或者其他有用的指令
- 缓存刷新机制:MIPS CPUs有两个独立的cache(缓冲):指令cache和数据cache。指令和数据分别在两个不同的缓存中。当缓存满了,会触发flush,将数据写回到主内存。攻击者的攻击payload通常会被应用当作数据来处理,存储在数据缓存中,当payload触发漏洞,劫持程序执行流程时,会去执行内存中的shellcode,如果数据缓存没有触发flush的话,shellcode依然存储在缓存中,而没有写入主内存。这会导致程序执行了本该存储shellcode的地址处随机的代码,导致不可预知的后果(通常执行sleep(1)刷新)
函数调用
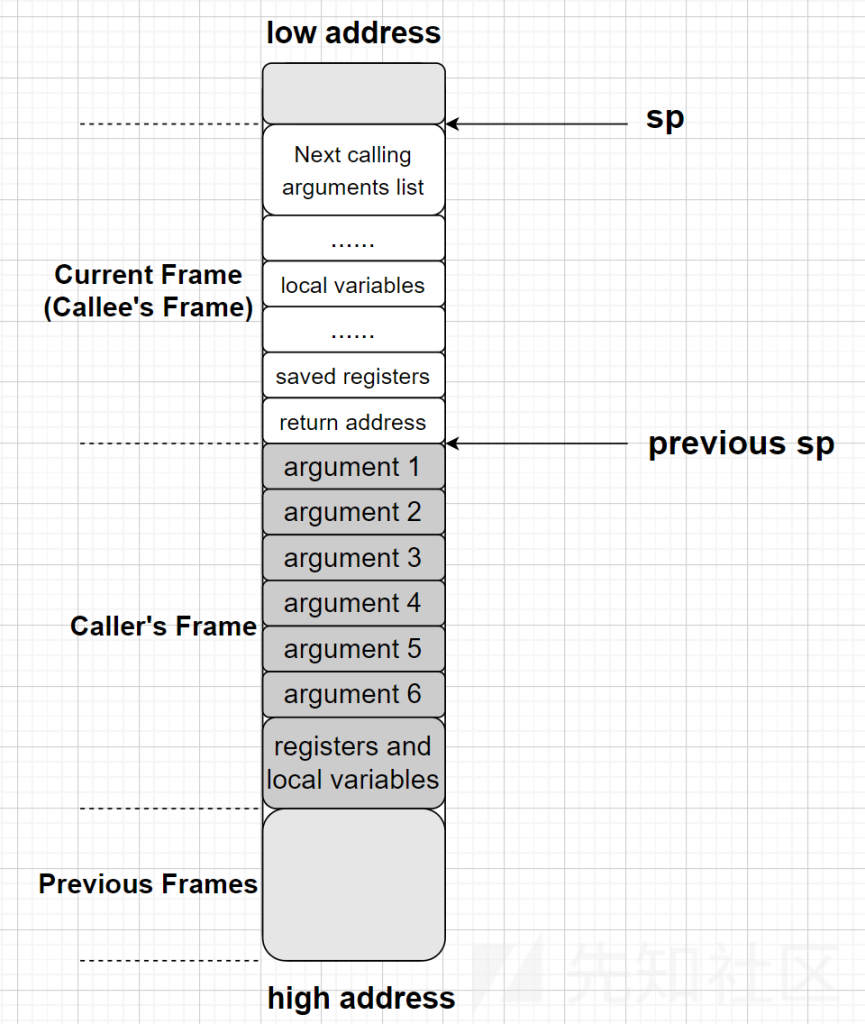
函数调用时传参:如果函数的参数小于等于四个,那么会使用$a0~$a3寄存器来存放参数。如果参数多余四个,那么多余的参数则存放到栈里(同时也会预留出前四个参数的内存空间,因为被调用者使用前四个参数时,会统一将参数放到保留的栈空间),具体情况是函数A调用函数B,调用者函数(函数A)会在自己的栈顶预留一部分空间来保存被调用者(函数B)的参数,称之为调用参数空间
gdb调试
#!/bin/bash
# Ensure the script exits on error
set -e
# Define variables for file name, GDB port, and architecture
target_file="test_mipsel_32"
gdb_port="1234"
# Check if the target file exists
if [ ! -f "$target_file" ]; then
echo "Error: Target file '$target_file' does not exist."
exit 1
fi
# Step 1: Start QEMU with GDB server enabled
echo "Starting QEMU with GDB server on port $gdb_port..."
qemu-mipsel -L /usr/mipsel-linux-gnu/ -g $gdb_port "$target_file" &
qemu_pid=$!
# Wait for QEMU to be ready
sleep 2
echo "QEMU started with PID $qemu_pid."
# Step 2: Start GDB and connect to QEMU GDB server
mips_gdb="gdb-multiarch"
# Check if GDB is installed
if ! command -v $mips_gdb &> /dev/null; then
echo "Error: GDB ($mips_gdb) not found. Please install it and try again."
exit 1
fi
echo "Starting GDB and connecting to QEMU..."
$mips_gdb -ex "target remote :$gdb_port" "$target_file"
# Cleanup after GDB session ends
echo "Stopping QEMU..."
kill $qemu_pid
# End of script
自启动QEMU并使用GDB链接调试MIPS程序,将其保存为一个.sh文件,并运行就可以使用gdb调试了(自己改文件名)
QEMU库路径 (-L参数):
如果新目标文件需要不同的库路径,例如可能有不同的工具链和根文件系统,可以修改QEMU的-L参数路径:
qemu-mipsel -L /path/to/new/lib/ -g $gdb_port "$target_file" &
确保路径中包含与目标文件相对应的共享库和ld.so.1动态链接器。
添加和扩展调试功能
- GDB启动脚本(.gdbinit):
- 如果有一些常用的gdb命令,可以添加到gdb启动脚本中,比如设置断点,打印特定变量,查看寄存器等
- 修改gdb启动参数,添加更多的gdb命令:
$mips_gdb -ex "target remote :$gdb_port" -ex "break main" "$target_file"
这会在main函数上自动设置一个断点
- 环境变量:
- 如果目标程序依赖特定的环境变量,可以使用QEMU的-E选项设置环境变量
qemu-mipsel -L /usr/mipsel-linux-gnu/ -g $gdb_port -E VAR_NAME=VALUE "$target_file" &
这样就可以调试了
- 如果目标程序依赖特定的环境变量,可以使用QEMU的-E选项设置环境变量
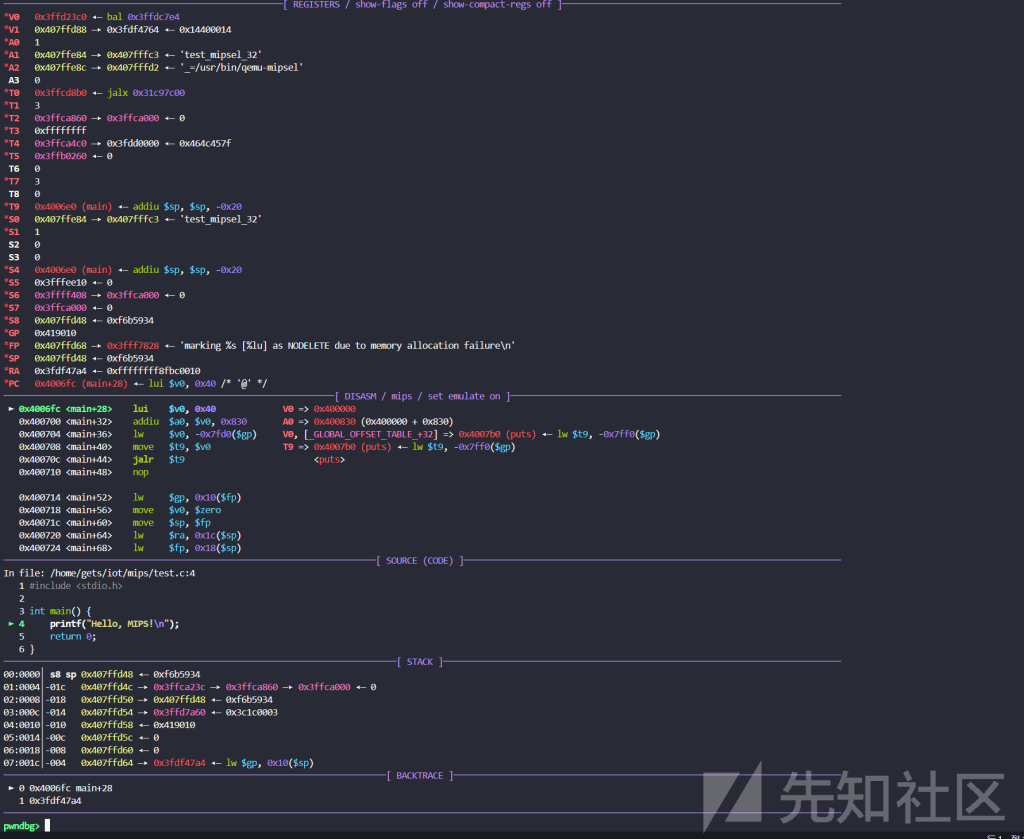
函数调用机制
在MIPS架构中,函数调用时通过jal(Jump and Link)指令完成的。jal指令会跳转到目标地址,同时将返回地址保存在$ra寄存器中
在截图,我们可以看到以下指令:
jalx 0x43fdc070:这条指令调用了一个函数,并将当前地址存入$ra(返回地址寄存器)中,以便函数执行结束后可以返回到原来的调用点。
函数返回进制
函数的返回是通过jr $ra指令完成的,它会跳转$ra寄存器中存储的地址,从而返回到调用函数的位置
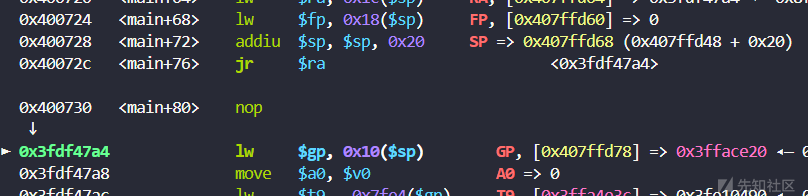
栈指针和帧指针
在函数调用过程,MIPS使用堆栈指$sp和帧指针$fp来管理函数的局部变量和保存调用环境。
截图中的指令说明了函数进入时对堆栈的操作:
addiu $sp, $sp, -0x20:这条指令将栈指针$sp向下移动32个字节,以为当前函数调用创建新的栈帧。这是典型的函数进入操作,用于为局部变量和保存寄存器分配空间。- 随后,我们看到一些sw指令,例如:
sw $ra, 0x1c($sp):将返回地址$ra存储到栈帧中,以便在函数结束时恢复。sw $fp, 0x18($sp):将帧指针$fp保存到栈中。
在这些指令之后,函数会更新帧指针:
move $fp, $sp:将当前栈指针的值赋给帧指针$fp,这样$fp可以作为当前栈帧的基准。
参数传递
在MIPS架构中,函数参数通常通过寄存器$a0到$a3传递。这些寄存器可以存储最多4个参数,如果参数超过4个,则剩余的参数会通过栈进行传递
在截图中可以看到:
$a0和$a1等寄存器在函数调用过程中会被用来存储传递给被调用函数的参数。
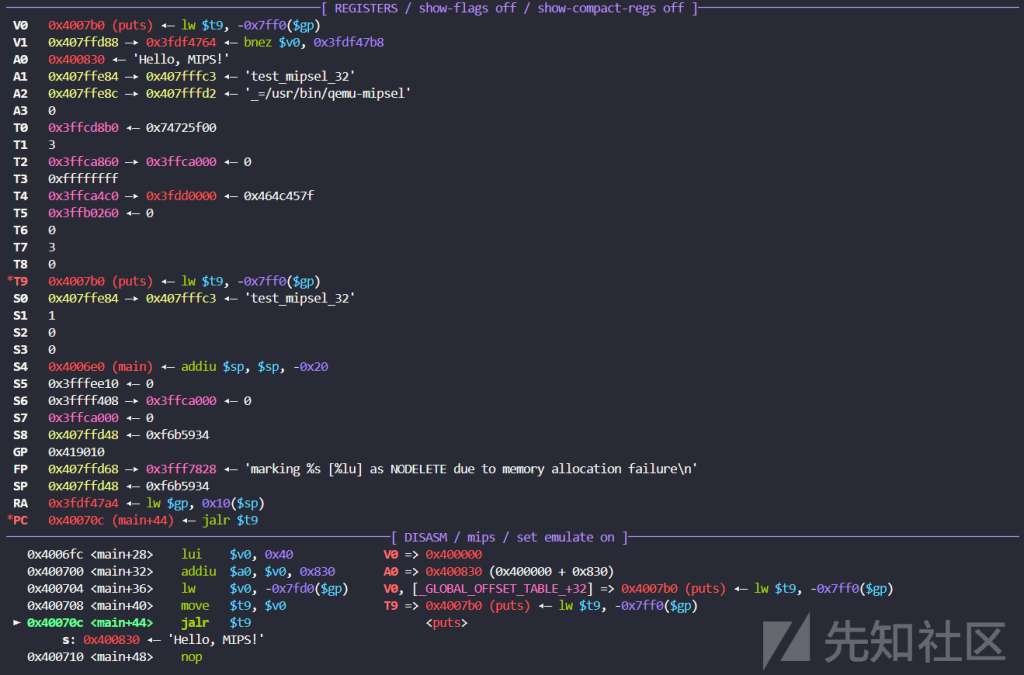
就像这里的v0里面就存的是puts函数的第一个参数
局部变量和保存寄存器
MIPS使用$t0到$t9作为临时寄存器,这些寄存器的值在函数调用过程中不需要被保留,而$s0到$s7则是保存寄存器,在函数调用过程中需要保存并在返回时恢复
在截图中可以看到多个sw和lw指令:
sw $s0, 0x10($sp):保存寄存器$s0到栈中,以便在函数返回时恢复其值。lw $s0, 0x10($sp):在函数返回前,将栈中保存的值重新加载到$s0。
内存访问和全局指针
在截图中的汇编代码,我们还看到涉及$gp(全局指针)的操作,例如加载全局变量或函数指针:
lw $t9, <offset>($gp):从全局指针$gp基础地址加偏移量的位置加载一个值到$t9,通常用于访问全局变量或调用全局函数。
函数调用中的延迟槽
MIPS架构使用延迟槽(delay slot)机制,在跳转或调用指令之后的下一条会在跳转前执行
调试区别
gdb和ida的调试会有区别,gdb多显示了$s8寄存器,基本上所有对$fp的操作都是对$s8的操作,比如寻址赋值
原因:$30,$fp/$s8,$30可以当作第9个Saved寄存器 $s8,也可以当作栈帧指针(Frame Pointer) $fp使用,这得看编译器的类型。上面表格的内容,第30号通用寄存器可以被叫做$fp或者$s8寄存器,它们用的是同一个“实体物理结构”,造成这种混乱的原因归结于不同编译器对此“物理结构”的使用,GNU MIPS C编译器将它用作帧指针(frame pointer)$fp,SGI的C编译器则将其当作保存寄存器使用$s8,后者的使用节省了调用和返回开销,增加了生成代码的复杂性
执行main函数时无论是哪种表述方式,sw $fp,0x18($sp)存放到栈上的$fp($s8)和$sp指向同一个栈内存地址,即,mips的函数在addiu开栈帧之后会立即move移动到$fp到$sp的位置,这点与x86不同
所以x86和MIPS_32的开辟栈帧的方式是不同的,但最终栈帧结构相同,且均可以将$fp到$sp类比为$esp和$ebp对比如下
总:帧指针$fp在调用过程中起着锚定的作用,在子过程被调用时会将旧的$fp压栈,在将$fp指向新产生栈帧固定位置,这样当前栈帧就有了$fp当一个哨兵,承担两个关键任务
- 无论
$sp怎么变,但只要直到栈中保存的数据相对于$fp的偏移,就可以将内存中的数据顺利取出 - 但如果
$sp在子过程为自己分配了栈空间后又发生了变化,那么子过程返回前$fp还需要帮$sp恢复原值($sp恢复原值也就是释放了当前子进程占用的栈空间)
因为gdb的显示方式不太一样,所以某些指令要多进行一步操作 jal parent_func(jal 0x400888)与nop
调用非叶子函数parent_func,还是先看ida:执行jal指令会将jal指令+0xC即返回地址
存入到$ra中,
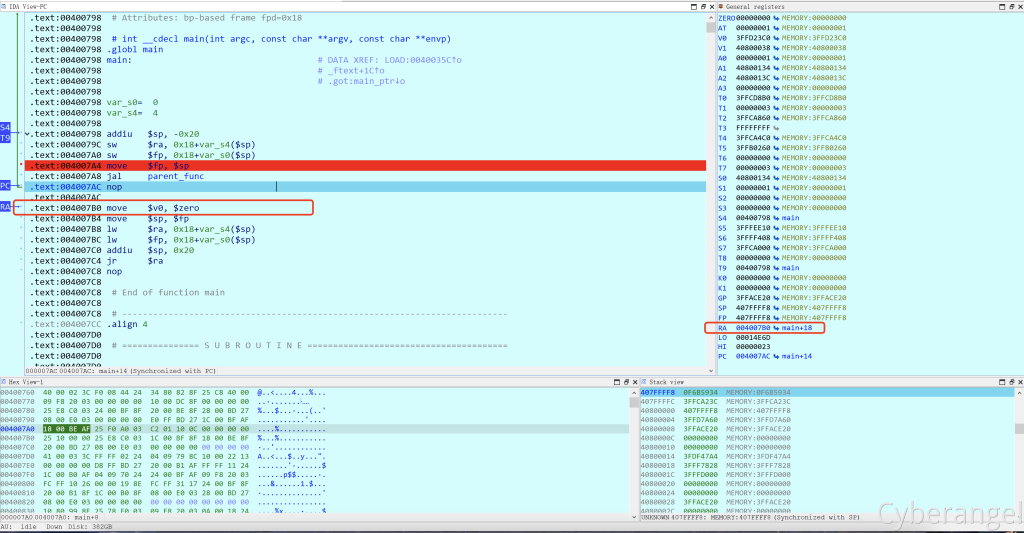
然后nop滑动到parent_func函数执行代码:
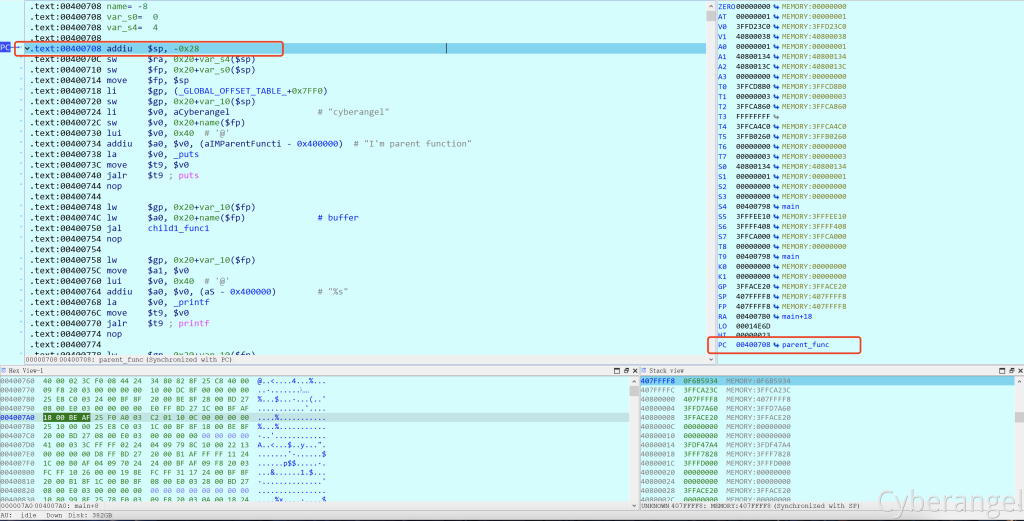
当函数A调用其他函数B时,函数调用指令如jal会将函数B的返回地址存入$ra中,然后nop滑动执行函数B,调用前后$sp和$fp值不变且相等,出现nop滑动时可能跟mips的流水线概念有关
流水线和Cache
计算机CPU处理速度和内存读取速度的匹配问题是提高cpu工作效率的关键,为了加速对内存的访问,CPU设计中引入了Cache。cache,即一个小的高速内存,用来拷贝内存中的一段数据,cache中最小的数据单元是line,每个line对应一小段内存地址(常见的line大小为64字节)。每个line不仅包含从主内存读取的数据,还包含其他地址信息(TAG)和状态信息。当cpu想要访问内存中的数据时。先由内存管理单元搜索cache,如果数据存在,则立即返回给CPU,这称为Cache命中;如果不存在,则称为Cache未命中。此时,内存管理单元再去主内存中查找相关数据,返回给CPU并在cache中留下备份,cache当然不知道CPU下一步需要什么数据,所以它只能保留CPU最近使用过的数据。如果需要为新拷贝的主内存数据,它就会选择合适的数据丢弃,这涉及Cache替换策略算法
cache大约9成时间能够提供CPU想要的数据,所以大大提高了CPU读取数据的速率,从而提高了流水线的工作效率
因为指令不同于数据,是只读属性,所以MIPS架构采用哈弗结构,将数据Cache和指令Cache分开,这样就可以读取指令和读写变量了
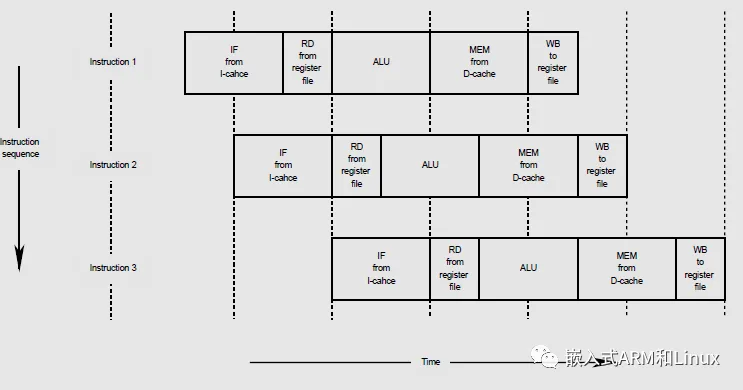
MIPS-5级流水线
- 取指令-IF
从I-Cache中取要执行的指令 - 读寄存器-RD
取CPU寄存器中的值 - 算术,逻辑运算-ALU
执行算术或逻辑运算(浮点运算和乘除运算在一个时钟周期内无法完成(跟FPU相关)) - 读写内存-MEM
也就是读写D-Cache,至于为什么说读写数据缓存,是因为内存的读写速度太慢,无法满足CPU的需要,所以出现了D-Cache这种高速缓存,但即便如此,在读写D-Cache期间,平均每4条指令就会有3条指令什么也做不到。但是,每条指令在这个阶段都应该是独占数据总线的,不然会造成访问D-Cache冲突。这就是内存屏障和总线锁存在的理由 - 写回寄存器-Writeback
将结果写入寄存器
这种流水线架构可以提高指令执行的并行度和效率,同时保持流水线的平衡和稳定性。
实际上有些MIPS架构的CPU会有更长的流水线或其他不同
流水线的规定同时限制了指令
所有指令具有相同的长度(32位),读取指令使用相同的时间,降低了流水线的复杂度,比如,指令中没有足够的位用来编码复杂的寻址模式,这种限制,这导致了MIPS占用更多内存空间
MIPS的流水线设计拍出来对内存变量进行任何操作的指令的实现,内存数据的获取只能在阶段4,这对于算术逻辑单元有些延迟,内存访问只能通过load或store指令进行,一些编译器高效优化的要求和流水线设计的要求是兼容的,所以MIPS架构的CPU具有32个通用寄存器,使用具有三个操作数的算术/逻辑指令。编译器会尽量不用复杂指令
MIPS指令集特点
限制
- 所有指令都是32位长度,没有指令仅占用2个或3个字节的内存空间,也没有指令超过4个字节,导致加载32位常数需要至少两条指令,一个32位指令没有足够的位为操作数和目标寄存器进行编码,MIPS设计者为两条指令保留了26位,即跳转jump指令,一个跳转到指定的目标地址,一个跳转到子程序,其他的指令都只有16位留给常数,条件分支被限制到了64k的作用范围
- 指令操作必须适合流水线,在正确阶段和一个时钟周期内完成,比如,寄存器写回操作只提供写一个值到寄存器中,所以指令在这个阶段只能改变某个寄存器的内容
乘除指令无法在一个时钟周期内完成,MIPS的CPU使用策略就是将这部分操作分配到单独的一个流水线进行操作 - 三个操作数的指令,使复杂表达式有更大优化空间,而算术/逻辑运算指令不需要存储操作,所以有足够的位来表示两个源操作寄存器和一个目的寄存器
- 32个通用寄存器,通用寄存器的个数由软件需求驱动,32个通用寄存器是现代计算机架构中常用的数量,如果使用16个不能完全满足需要,而32个足以覆盖最大最复杂的函数调用关系,但是,使用64个寄存器需要占用指令中更多的位去编码寄存器,也会增加上下文切换时的负荷(需要保存的寄存器更多),寄存器的数量丰富,大小适中,提供了充足的存储空间和操作灵活性,减少了内存访问的次数,提高了程序的执行效率。
- 寄存器
$0总是返回一个0常数,0是最常用的一个常数,直接用一个寄存器表示可以减少常数向寄存器的加载操作 - 指令不含条件码,相比其他RISC架构,MIPS指令集的重要特性是没有任何条件标志。许多架构使用进位,零等多个标志,像X86等CISC复杂指令集架构的指令中有一些位专门表示是否根据结果设置这些标志位。就是一些RISC指令集架构也保留了一些这样的标志位,比如说ARM,尽管通常只有比较指令可以设置这些标志位。而MIPS使用了寄存器来保存这些信息,比较指令根据结果设置通用寄存器,条件分支指令检查判断这些通用寄存器,这样的操作有利于流水线架构的实现,使比较/分支指令不需要再依赖于算术/逻辑操作,彼此独立,它们之间的逻辑关系由软件实现。有效的条件分支要求,必须在半个时钟周期内做出是否要跳转的决定。MIPS架构通过尽可能简单的测试条件是否满足实现,比如,判断某个寄存器的值是否为符号位或者等于0,判断两个寄存器的值是否相等
- MIPS架构采用了加载/存储架构,只允许内存和寄存器之间的数据传输通过专门的加载和存储指令完成。这种架构简化了指令集,提高了指令执行的效率。
- 操作数通常以字对齐的方式存储在内存中,以提高内存访问效率。
寻址和内存访问 - 访问内存先load/store到寄存器中,不直接操作内存变量,所以先将其加载到寄存器中,然后对寄存器进行算术逻辑操作,完成后将结果存储到内存中对应的位置
- 只有一种数据寻址模式,寄存器寻址,几乎所有加载和存储都是通过寄存器基址加上16位偏移实现的
- 字节寻址,MIPS架构中的寄存器是一个整体,所有的操作都是对整个寄存器的操作。所以,无法实现字节或者半字的操作,但是c语言之类的语法又可以按照字节或者半字进行操作,MIPS架构采取的方式就是,提供一组load/store指令,分别加载字节,半字或WORD大小的内存变量。一旦数据加载到寄存器中,它就看作为一个寄存器长度大小的数据(如,32位架构是32位整数,64位被看作64位)。所以对于字节或者半字的load操作,还需要考虑符号位。延伸出来两种加载指令的形式:符号扩展或零扩展
- load/store操作必须对齐:MIPS架构的内存访问必须按照对齐方式进行,字节可以是任何地址,但半字必须是偶数地址对齐,WORD必须是4字节对齐的方式,CISC指令集架构的微处理器可以从任意地址处读取一个4字节的数据,但需要多花费一些时钟周期。MIPS指令集设计了一些特殊指令来简化未正确对齐的地址上load和store的工作
- 跳转指令:指令的长度限制为32位影响了想要大范围跳转的分支指令。MIPS指令最小的操作码域是6位,为跳转的目标地址保留了26位。因为内存中的指令代码都是4字节对齐的,最低两位不需要保存,那么允许访问的程序范围就是2^28,等于256mb,这个地址不是相对于PC(程序计数器)的,而是被解释为256M的代码段中一个绝对地址。这样依赖,对于大于256M的单个程序非常不便,虽然可以使用寄存器保存跳转目标,然后再使用跳转指令跳转到32位地址的任何地方
条件分支就只有16位的偏移量,对于4字节对齐的内存空间,其访问的范围是2^18B。这里的地址可以解释为相对PC寄存器的正负范围,所以编译器只有知道目标地址在分支指令前后128kb的范围内才能正确的编码条件分支指令
没有的特性 - 没有字节或半字算术运算:所有算术和逻辑操作都是基于32位完成的,操作字节或者半字要求更多的额外资源和更多的操作码,所以一半不推荐使用,但是如果程序中显式的使用short或者char类型的数据进行运算,支持MIPS架构的编译器必须额外的插入一些机器指令,保证结果能够像在真正的16位或8位机器上那样正确运行
- 没有对堆栈寄存器的特定支持:虽然传统意义上的MIPS汇编代码也会定义一个寄存器作为堆栈指针寄存器,但是,硬件上没有规定哪个寄存器是特定的sp寄存器,而arm和x96则有特定的sp寄存器。对于函数调用的实现,有一些约定俗称的格式,比如System V ABI。有一种推荐的子程序调用时堆栈栈帧布局,这样可以混合使用汇编和c语言编程,使用不同的编译器选项进行编译,但和硬件无关,需要人为实现,堆栈的pop不符合流水线的执行,因为要写两个寄存器
- 最少的子程序支持,跳转指令具有跳转(jump)和链接(link)跳转指令,把返回地址写入到一个固定的寄存器中,默认使用
$31作为返回地址寄存器
这比把返回地址保存到堆栈中更简单,把分支指令和内存访问指令分离开,当调用不需要保存返回地址的子程序时,有助于提供效率 - 最少的中断处理,把程序重新运行的地址保存到一个特定寄存器中,修改机器状态,然后禁止中断,做完这些后,跳转到一段保存到低内存中预定义好的程序,之后的工作由软件控制。硬件上,MIPS只是保存了一个重新运行的地址,而如x86架构,还需保存eflags,cs,eip,ss和esp等寄存器
- 最少的异常处理,异常的硬件处理其实同中断处理一样,MIPS架构把中断当作异常的一种,MIPS的异常涵盖了CPU想要中断所有顺序的执行,调用软件处理程序所产生的所有时间,比如中断,试图访问物理地址不存在的虚拟内存或者其它事情都可以产生异常,如故意植入的trap陷阱指令,像为了访问内核态程序的系统调用都是一种异常,所有异常都导致CPU的控制权传递给一个固定的入口点
对于任何异常,mips的cpu不会存储任何东西到堆栈上,也不会写内存或者保存任何寄存器。按约定,mips也保留了两个通用寄存器,让异常程序可以自举(在mips的cpu上,不使用寄存器是无法工作的)但是,对于一个旨在多架构上运行的,允许中断或陷阱(trap)的通用系统,这两个寄存器的值会随时发生变化
补:
异常和中断处理
MIPS架构提供了丰富的异常和中断处理机制,包括硬件异常和软件异常,以及外部中断和内部中断。
处理器可以通过异常向量表来响应不同类型的异常和中断事件,保证系统的稳定性和可靠性。
流水线的延迟
分支延迟
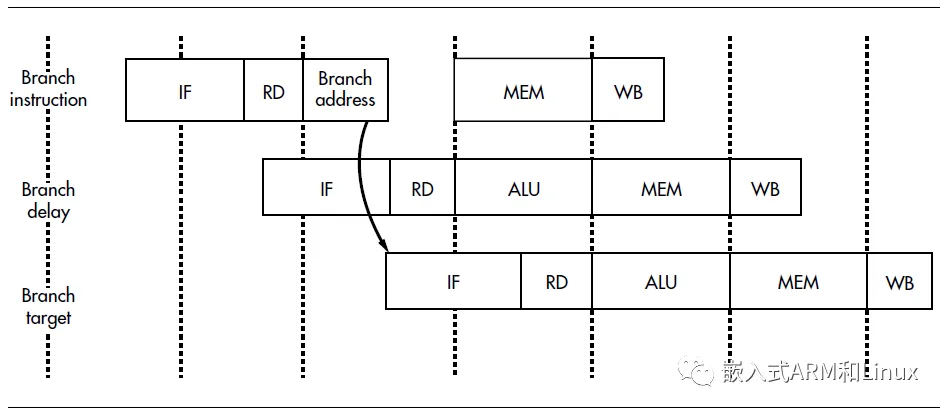
- 如上图,当一个jump指令在读取阶段时,又产生了新的PC寄存器值,jump指令后的指令也被启动了,MIPS架构规定,分支指令之后的指令总是在分支目标指令之前执行,跟随在分支指令后的指令位置被称为分支延迟槽,物理意义上,对应上图就是横向上的一格,对于分支延迟槽,如果硬件不做任何特殊处理的话,决定是否跳转以及跳转的目标地址等,这些工作会在ALU阶段结束时才能完成,此时即便是在下下个流水线槽都来不及提供一个指令地址
但是分支指令的重要性足以给其特殊处理,从上图可以看出,通过特殊处理,ALU阶段可以在半个时钟周期内就使目标地址可用,连同取地址提前的半个周期,刚好在下下个流水线槽得到分支目标地址作为指令开始执行,所以CPU控制单元执行的顺序是,分支指令,分支延迟槽指令,然后是分支目标指令,中间无延时
对于条件分支指令,至少保证位于分支延迟槽的指令对两个分支都是无害的。如果是在没有可以安排的指令,可以添加一个nop指令。
数据加载延迟(加载延时槽)
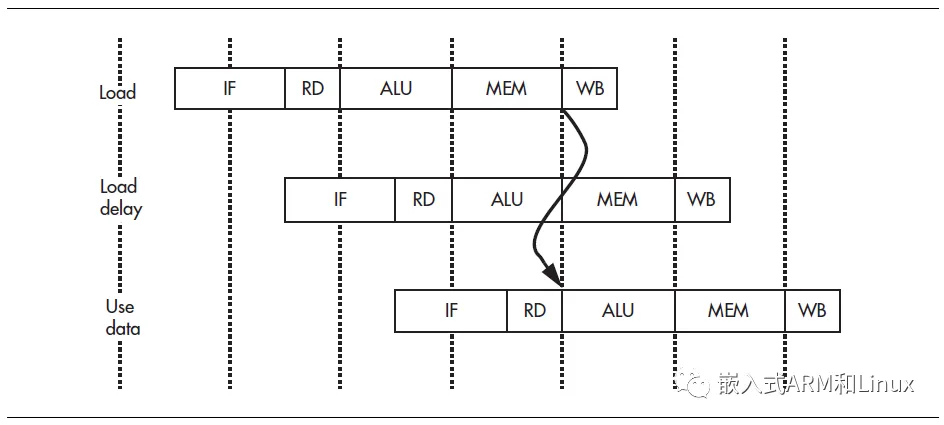
简化的流水线的另一个结果就是,当下一条指令到达ALU阶段时,上一条load指令的数据才开始从cache或内存中到达,也就是,load指令的下一条指令还是不能使用数据的
那么load指令后的位置,就称为加载延时槽,带有优化的编译器总是尝试利用这个加载延时槽,有时候,编译器会把这个位置填充一个nop操作,最新的MIPS架构CPU上,load操作也采用了互锁机制,如果尝试过早使用这个数据,CPU会停止执行,等待这个数据到达,但是早期CPU没有互锁机制,过早的使用这个数据会导致不可预料的结果
常见的MIPS架构芯片


MIPS处理器:
- MIPS Technologies开发了许多MIPS架构的处理器。
- 其中一些常见的处理器系列包括MIPS32和MIPS64系列,它们分别支持32位和64位地址空间。
- MIPS处理器被广泛应用于嵌入式系统、网络设备、数字信号处理器等领域。
嵌入式系统芯片:
- MIPS架构在嵌入式系统中有着广泛的应用,包括智能手机、平板电脑、路由器、智能家居设备等。
- 一些厂商如博通(Broadcom)、高通(Qualcomm)、联发科(MediaTek)等生产了基于MIPS架构的嵌入式系统芯片。
网络处理器:
- MIPS架构被广泛用于网络设备中的处理器,如路由器、交换机、防火墙等。
- Cavium(卡维姆,现在是马拉维(Marvell)的一部分)是一家生产MIPS架构网络处理器的知名厂商。
数字信号处理器(DSP):
- MIPS架构也被用于数字信号处理器(DSP)领域,用于音频处理、图像处理、视频处理等应用。
- 一些厂商如爱立信(Ericsson)、高通(Qualcomm)等生产了基于MIPS架构的DSP芯片。
存储控制器:
- MIPS架构还被用于存储控制器领域,如硬盘控制器、闪存控制器等。
- 一些厂商生产了用于存储设备的MIPS架构芯片,提供高性能的存储解决方案。
学习文章:
https://www.yuque.com/cyberangel/rg9gdm/yxb067
https://xz.aliyun.com/news/15460








